Egocentric Video Description based on Temporally-Linked Sequences
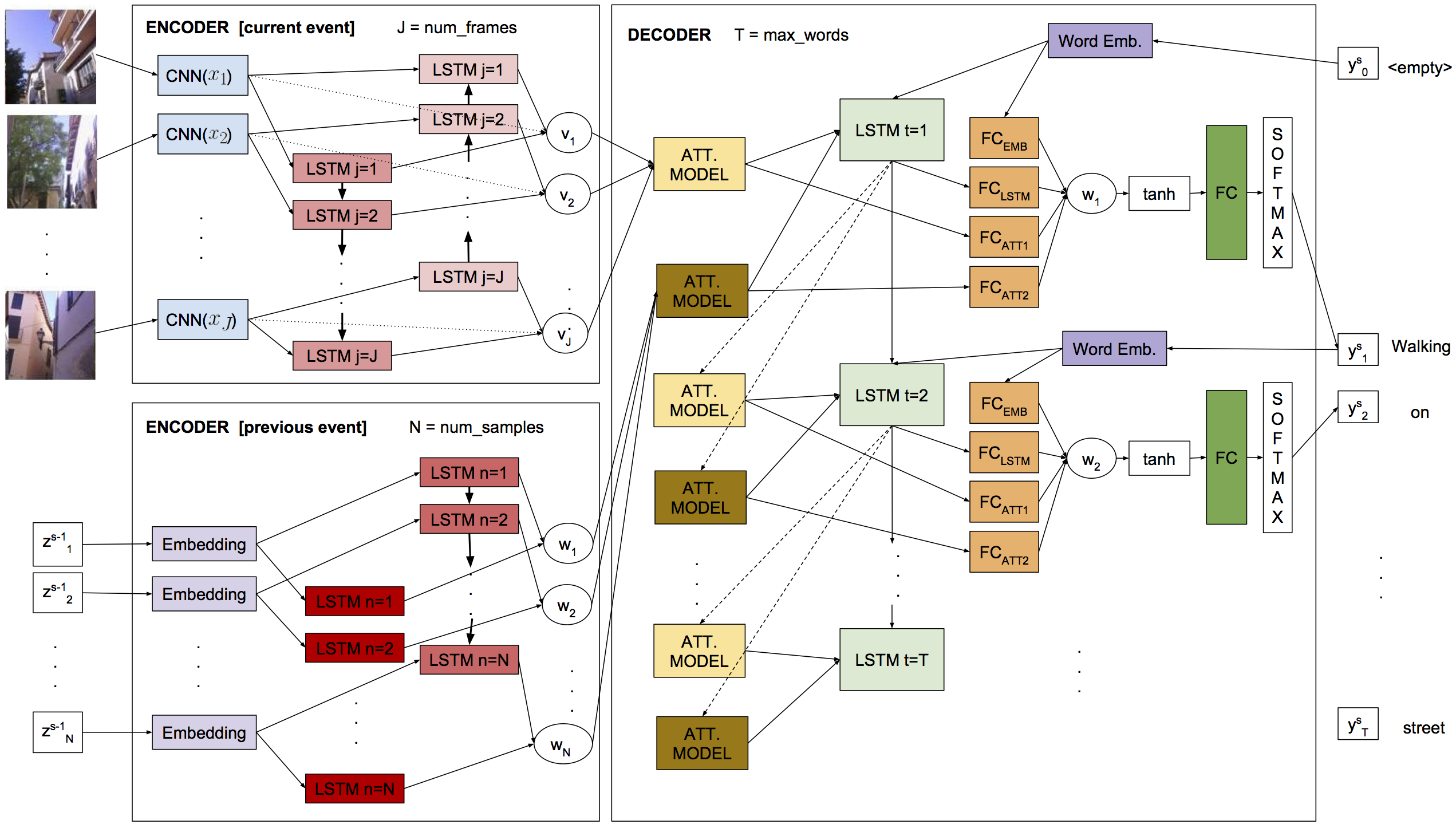
Egocentric vision consists in acquiring images along the day from a first person point-of-view using wearable cameras. The automatic analysis of this information allows to discover daily patterns for improving the quality of life of the user. A natural topic that arises in egocentric vision is storytelling, that is, how to understand and tell the story relying behind the pictures. In this paper, we tackle storytelling as an egocentric sequences description problem. We propose a novel methodology that exploits information from temporally neighboring events, matching precisely the nature of egocentric sequences. Furthermore, we present a new method for multimodal data fusion consisting on a multi-input attention recurrent network. We also publish the first dataset for egocentric image sequences description, consisting of 1,339 events with 3,991 descriptions, from 55 days acquired by 11 people. Furthermore, we prove that our proposal outperforms classical attentional encoder-decoder methods for video description.
PDF Abstract
 MSVD
MSVD
