Deep Transformers Thirst for Comprehensive-Frequency Data
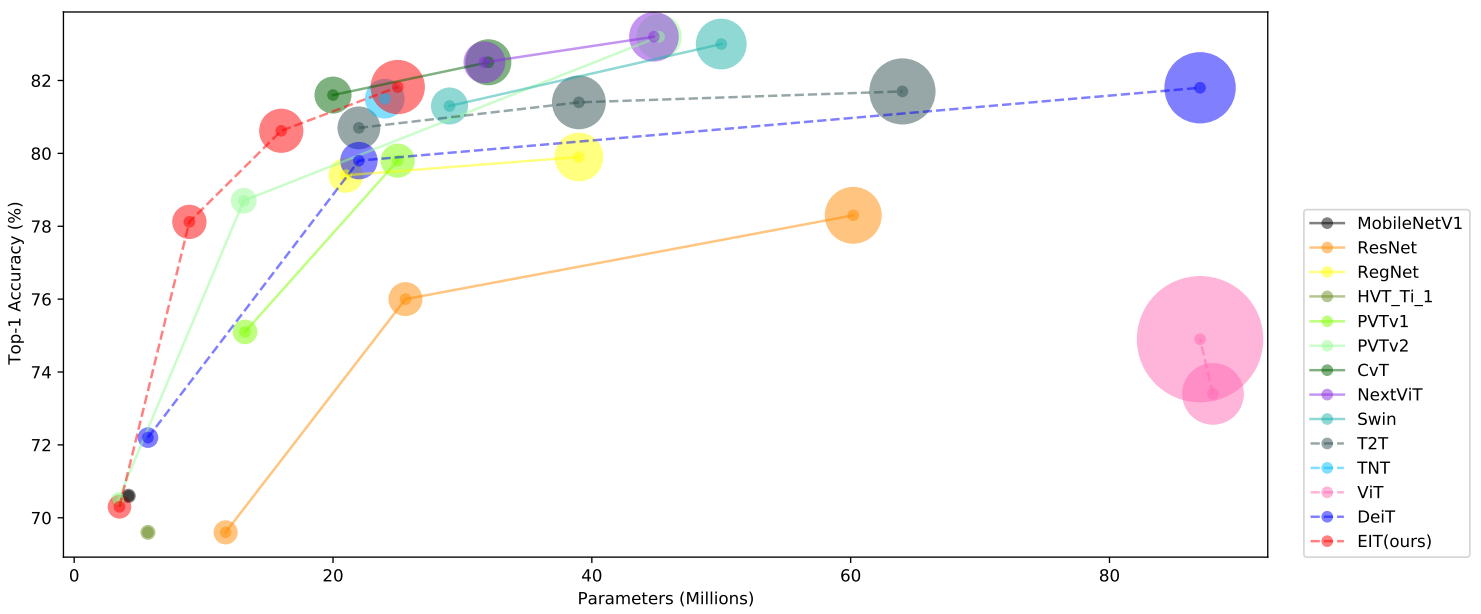
Current researches indicate that inductive bias (IB) can improve Vision Transformer (ViT) performance. However, they introduce a pyramid structure concurrently to counteract the incremental FLOPs and parameters caused by introducing IB. This structure destroys the unification of computer vision and natural language processing (NLP) and complicates the model. We study an NLP model called LSRA, which introduces IB with a pyramid-free structure. We analyze why it outperforms ViT, discovering that introducing IB increases the share of high-frequency data in each layer, giving "attention" to more information. As a result, the heads notice more diverse information, showing better performance. To further explore the potential of transformers, we propose EIT, which Efficiently introduces IB to ViT with a novel decreasing convolutional structure under a pyramid-free structure. EIT achieves competitive performance with the state-of-the-art (SOTA) methods on ImageNet-1K and achieves SOTA performance over the same scale models which have the pyramid-free structure.
PDF Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
