Embodied Question Answering
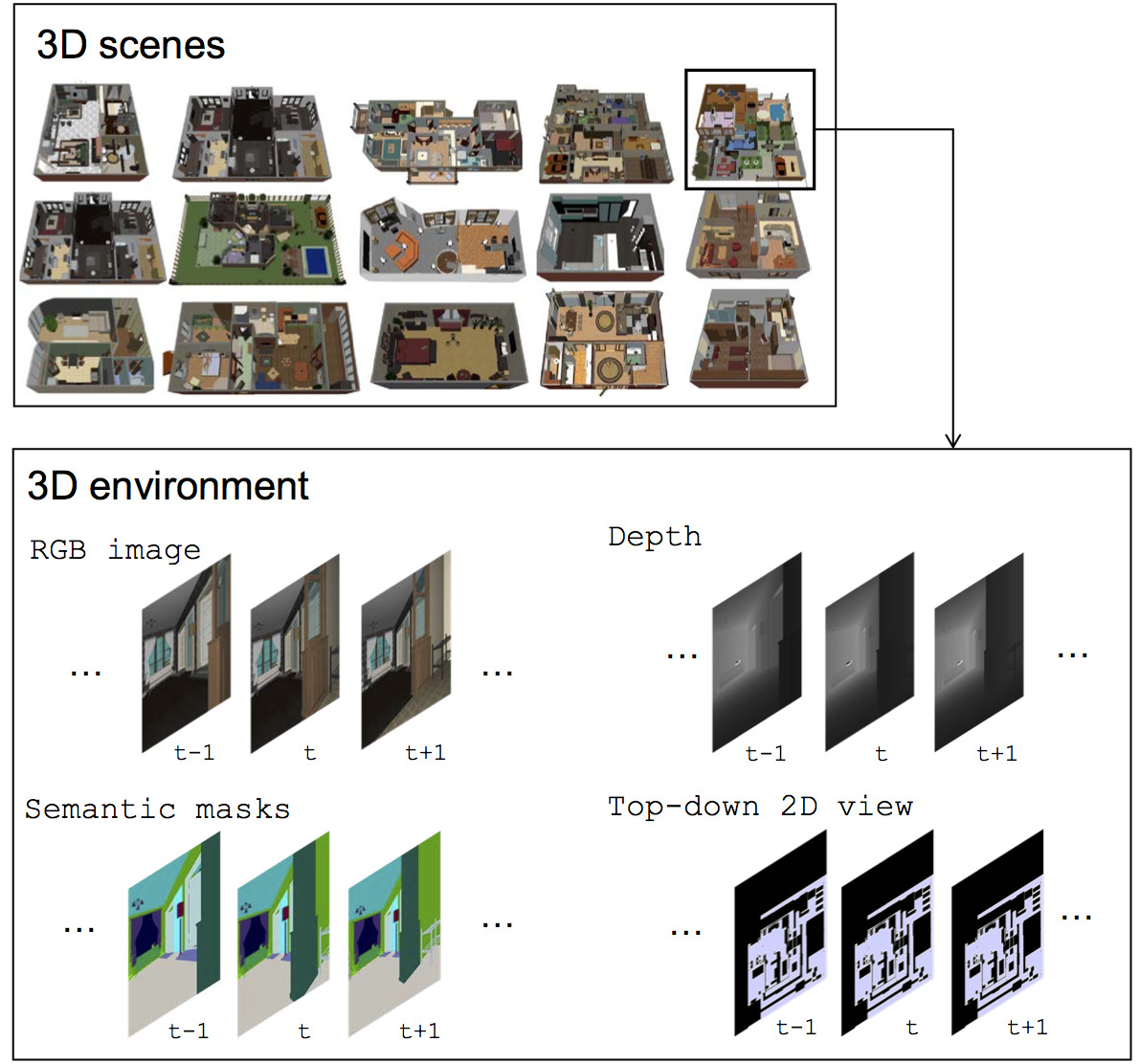
We present a new AI task -- Embodied Question Answering (EmbodiedQA) -- where an agent is spawned at a random location in a 3D environment and asked a question ("What color is the car?"). In order to answer, the agent must first intelligently navigate to explore the environment, gather information through first-person (egocentric) vision, and then answer the question ("orange"). This challenging task requires a range of AI skills -- active perception, language understanding, goal-driven navigation, commonsense reasoning, and grounding of language into actions. In this work, we develop the environments, end-to-end-trained reinforcement learning agents, and evaluation protocols for EmbodiedQA.
PDF Abstract CVPR 2018 PDF CVPR 2018 AbstractCode



Datasets
 EQA
EQA
 Visual Question Answering
Visual Question Answering
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
