EmbraceNet: A robust deep learning architecture for multimodal classification
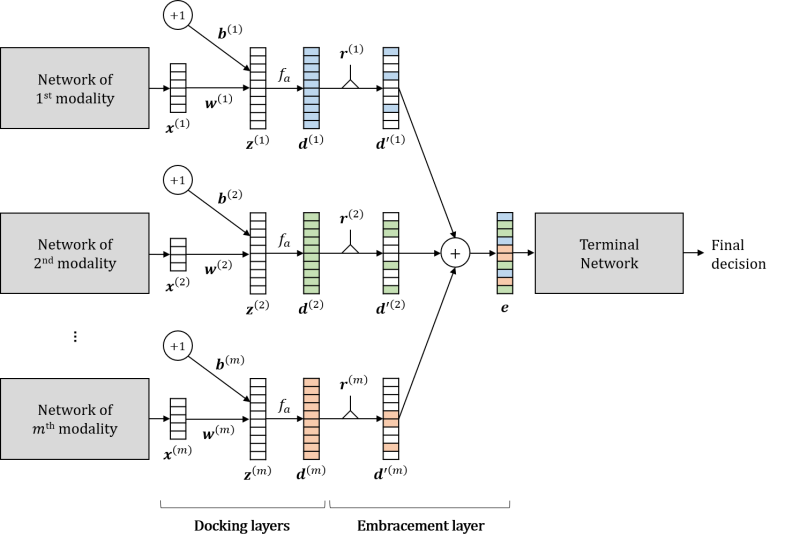
Classification using multimodal data arises in many machine learning applications. It is crucial not only to model cross-modal relationship effectively but also to ensure robustness against loss of part of data or modalities. In this paper, we propose a novel deep learning-based multimodal fusion architecture for classification tasks, which guarantees compatibility with any kind of learning models, deals with cross-modal information carefully, and prevents performance degradation due to partial absence of data. We employ two datasets for multimodal classification tasks, build models based on our architecture and other state-of-the-art models, and analyze their performance on various situations. The results show that our architecture outperforms the other multimodal fusion architectures when some parts of data are not available.
PDF Abstract



 MNIST
MNIST
 Fashion-MNIST
Fashion-MNIST
