EncT5: A Framework for Fine-tuning T5 as Non-autoregressive Models
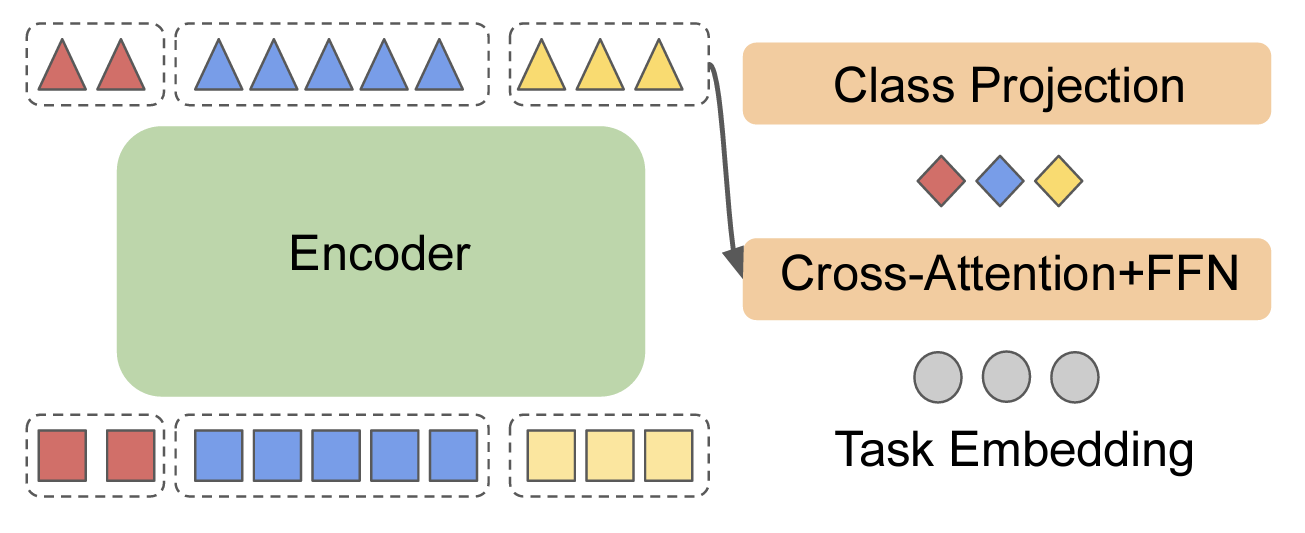
Pre-trained encoder-decoder transformer architectures have become increasingly popular recently with the advent of T5 models. T5 has also become more favorable over other architectures like BERT due to the amount of data that it is pre-trained on, increased scale of model parameter sizes and easy applicability to a diverse set of tasks due to the generative nature of the model. While being able to generalize to a wide variety of tasks, it is not clear that encoder-decoder architectures are the most efficient for fine-tuning tasks that don't require auto-regressive decoding. In this work, we study fine-tuning pre-trained encoder-decoder models for tasks such as classification, multi-label classification, and structured prediction. We propose \textbf{EncT5}, a framework for these problems, and illustrate instantiations for these tasks. Our experiment results show that EncT5 has advantages over T5 such as efficiency and usability out performs BERT when evaluated on publicly available pre-trained checkpoints.
PDF Abstract


 GLUE
GLUE
