End-to-end music source separation: is it possible in the waveform domain?
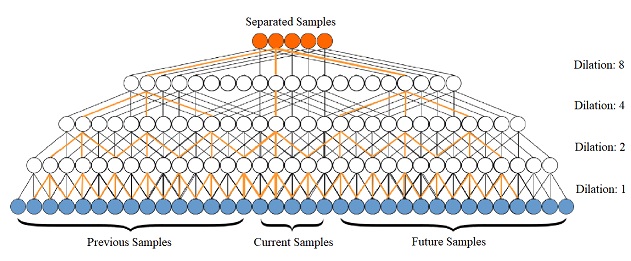
Most of the currently successful source separation techniques use the magnitude spectrogram as input, and are therefore by default omitting part of the signal: the phase. To avoid omitting potentially useful information, we study the viability of using end-to-end models for music source separation --- which take into account all the information available in the raw audio signal, including the phase. Although during the last decades end-to-end music source separation has been considered almost unattainable, our results confirm that waveform-based models can perform similarly (if not better) than a spectrogram-based deep learning model. Namely: a Wavenet-based model we propose and Wave-U-Net can outperform DeepConvSep, a recent spectrogram-based deep learning model.
PDF Abstract


 MUSDB18
MUSDB18

