End-to-End Video Text Spotting with Transformer
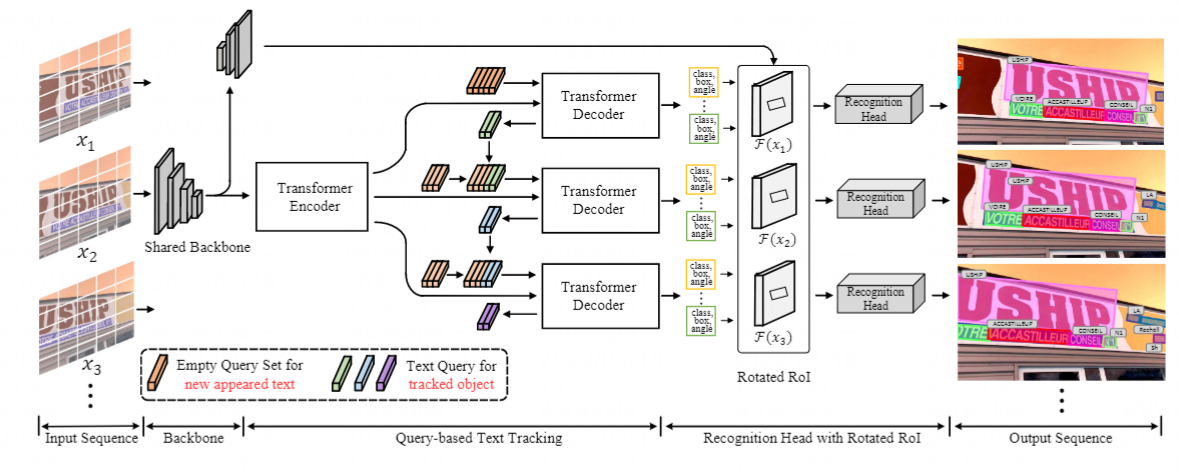
Recent video text spotting methods usually require the three-staged pipeline, i.e., detecting text in individual images, recognizing localized text, tracking text streams with post-processing to generate final results. These methods typically follow the tracking-by-match paradigm and develop sophisticated pipelines. In this paper, rooted in Transformer sequence modeling, we propose a simple, but effective end-to-end video text DEtection, Tracking, and Recognition framework (TransDETR). TransDETR mainly includes two advantages: 1) Different from the explicit match paradigm in the adjacent frame, TransDETR tracks and recognizes each text implicitly by the different query termed text query over long-range temporal sequence (more than 7 frames). 2) TransDETR is the first end-to-end trainable video text spotting framework, which simultaneously addresses the three sub-tasks (e.g., text detection, tracking, recognition). Extensive experiments in four video text datasets (i.e.,ICDAR2013 Video, ICDAR2015 Video, Minetto, and YouTube Video Text) are conducted to demonstrate that TransDETR achieves state-of-the-art performance with up to around 8.0% improvements on video text spotting tasks. The code of TransDETR can be found at https://github.com/weijiawu/TransDETR.
PDF Abstract

 ICDAR 2013
ICDAR 2013
 COCO-Text
COCO-Text
