Equivariant Multi-Modality Image Fusion
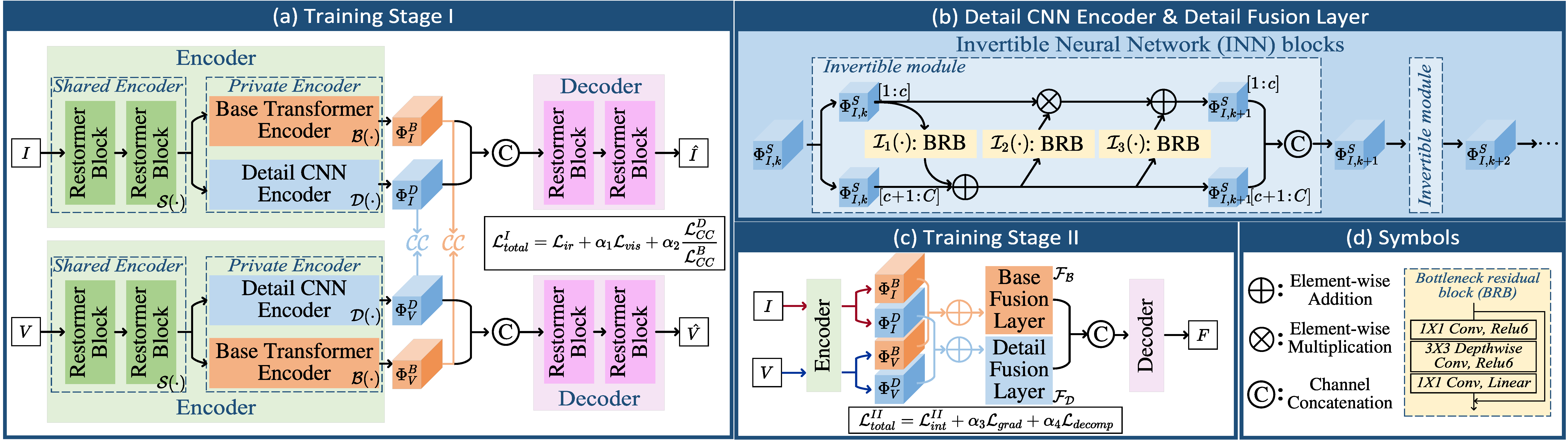
Multi-modality image fusion is a technique that combines information from different sensors or modalities, enabling the fused image to retain complementary features from each modality, such as functional highlights and texture details. However, effective training of such fusion models is challenging due to the scarcity of ground truth fusion data. To tackle this issue, we propose the Equivariant Multi-Modality imAge fusion (EMMA) paradigm for end-to-end self-supervised learning. Our approach is rooted in the prior knowledge that natural imaging responses are equivariant to certain transformations. Consequently, we introduce a novel training paradigm that encompasses a fusion module, a pseudo-sensing module, and an equivariant fusion module. These components enable the net training to follow the principles of the natural sensing-imaging process while satisfying the equivariant imaging prior. Extensive experiments confirm that EMMA yields high-quality fusion results for infrared-visible and medical images, concurrently facilitating downstream multi-modal segmentation and detection tasks. The code is available at https://github.com/Zhaozixiang1228/MMIF-EMMA.
PDF Abstract

