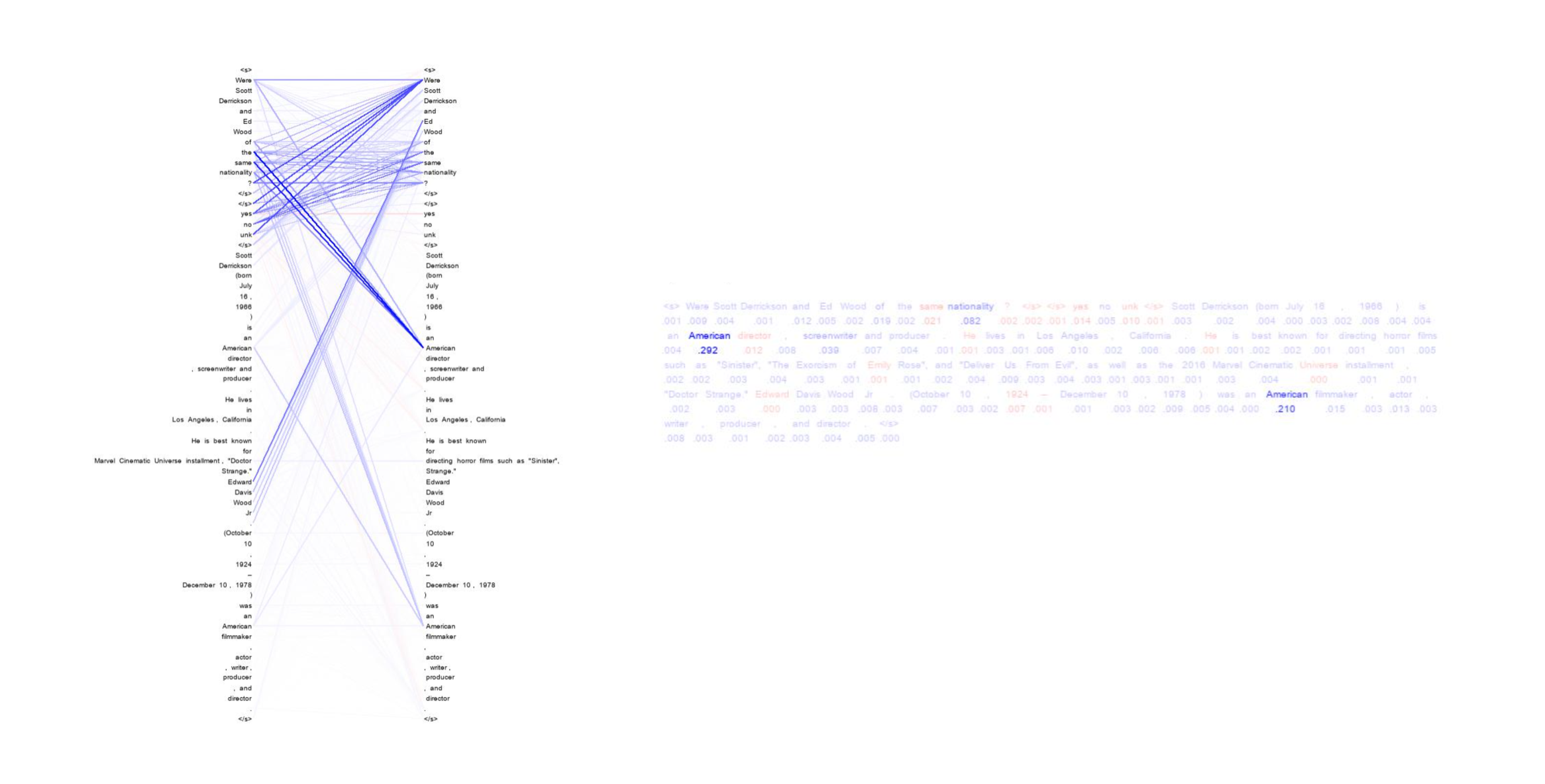
Connecting Attributions and QA Model Behavior on Realistic Counterfactuals
When a model attribution technique highlights a particular part of the input, a user might understand this highlight as making a statement about counterfactuals (Miller, 2019): if that part of the input were to change, the model's prediction might change as well. This paper investigates how well different attribution techniques align with this assumption on realistic counterfactuals in the case of reading comprehension (RC). RC is a particularly challenging test case, as token-level attributions that have been extensively studied in other NLP tasks such as sentiment analysis are less suitable to represent the reasoning that RC models perform. We construct counterfactual sets for three different RC settings, and through heuristics that can connect attribution methods' outputs to high-level model behavior, we can evaluate how useful different attribution methods and even different formats are for understanding counterfactuals. We find that pairwise attributions are better suited to RC than token-level attributions across these different RC settings, with our best performance coming from a modification that we propose to an existing pairwise attribution method.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract



 SQuAD
SQuAD
 HotpotQA
HotpotQA
