A Benchmark for Interpretability Methods in Deep Neural Networks
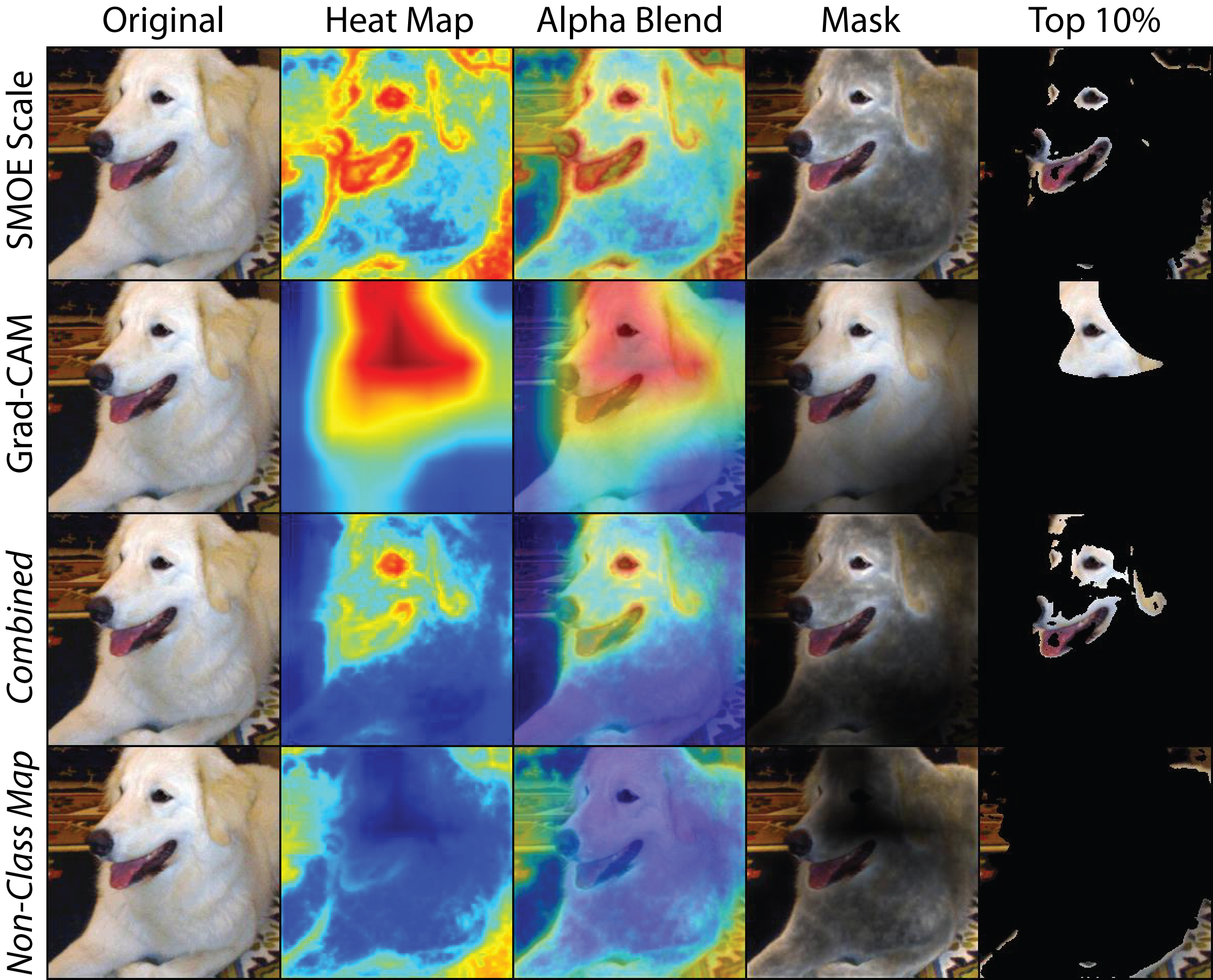
We propose an empirical measure of the approximate accuracy of feature importance estimates in deep neural networks. Our results across several large-scale image classification datasets show that many popular interpretability methods produce estimates of feature importance that are not better than a random designation of feature importance. Only certain ensemble based approaches---VarGrad and SmoothGrad-Squared---outperform such a random assignment of importance. The manner of ensembling remains critical, we show that some approaches do no better then the underlying method but carry a far higher computational burden.
PDF AbstractCode




 ImageNet
ImageNet
 Food-101
Food-101
 Birdsnap
Birdsnap
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
