Evaluating Language Model Finetuning Techniques for Low-resource Languages
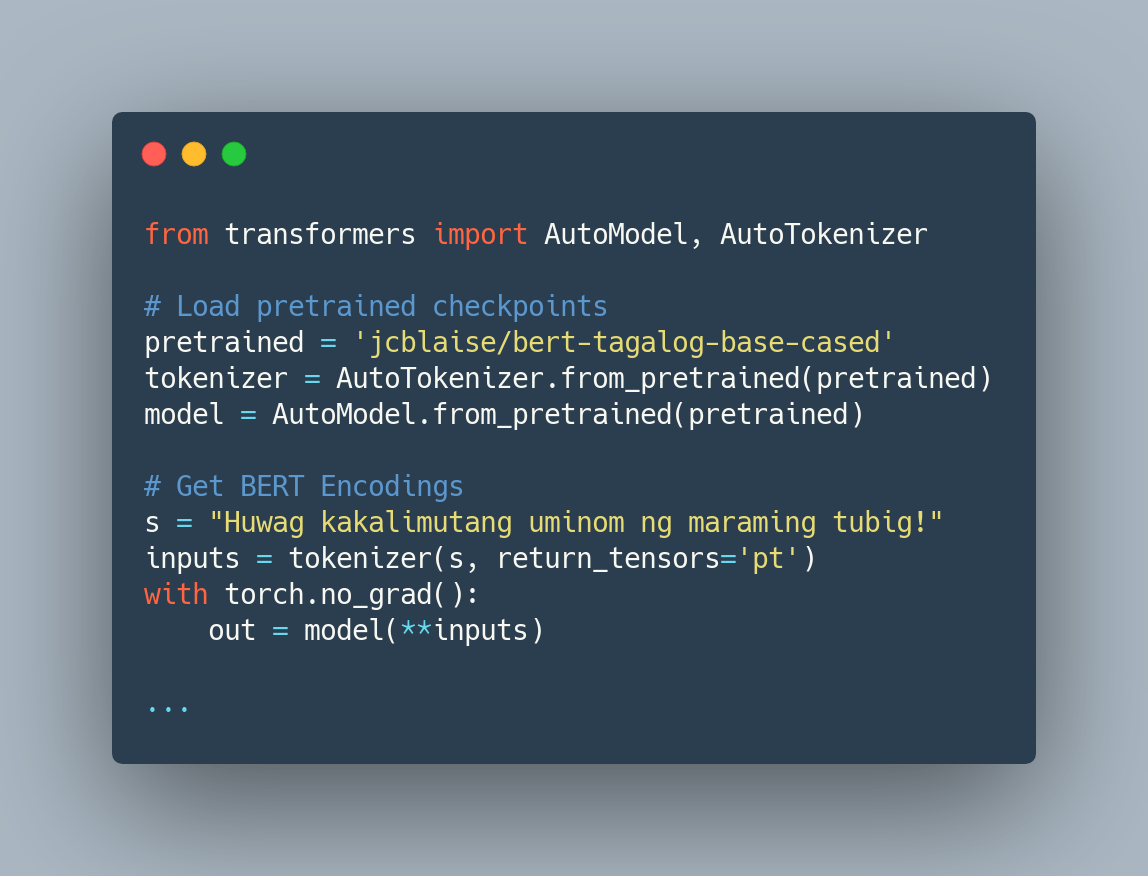
Unlike mainstream languages (such as English and French), low-resource languages often suffer from a lack of expert-annotated corpora and benchmark resources that make it hard to apply state-of-the-art techniques directly. In this paper, we alleviate this scarcity problem for the low-resourced Filipino language in two ways. First, we introduce a new benchmark language modeling dataset in Filipino which we call WikiText-TL-39. Second, we show that language model finetuning techniques such as BERT and ULMFiT can be used to consistently train robust classifiers in low-resource settings, experiencing at most a 0.0782 increase in validation error when the number of training examples is decreased from 10K to 1K while finetuning using a privately-held sentiment dataset.
PDF Abstract
Tasks

Datasets
Introduced in the Paper:
WikiText-TL-39