Explicit Document Modeling through Weighted Multiple-Instance Learning
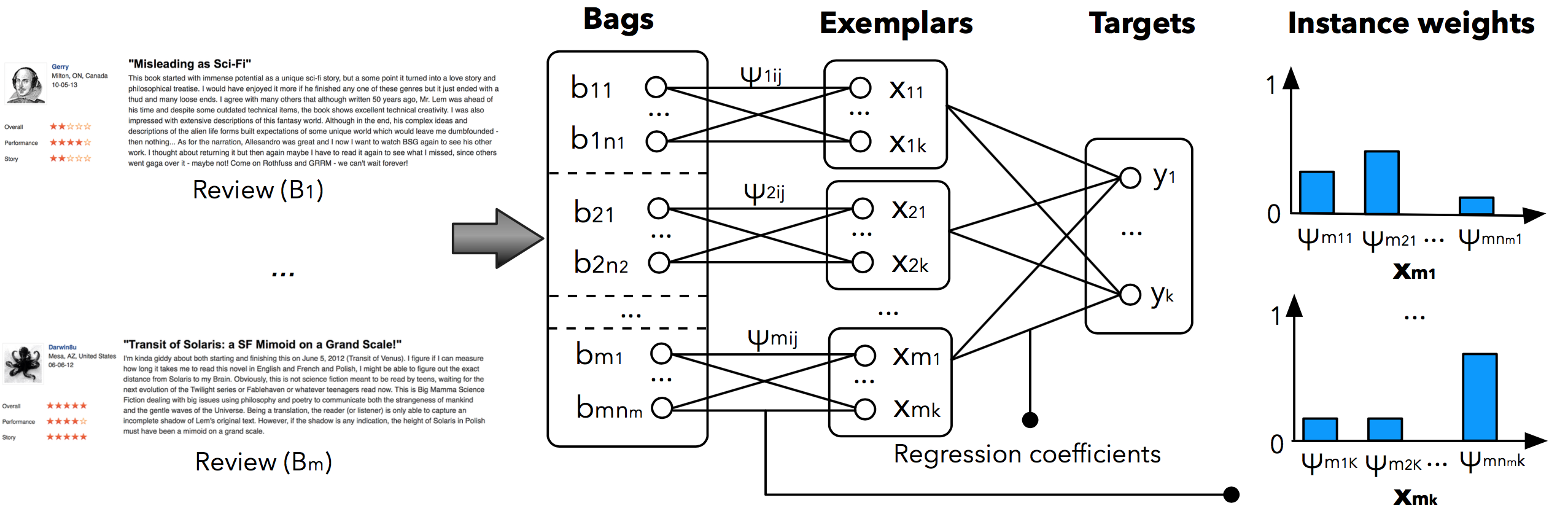
Representing documents is a crucial component in many NLP tasks, for instance predicting aspect ratings in reviews. Previous methods for this task treat documents globally and do not acknowledge that target categories are often assigned by their authors with generally no indication of the specific sentences that motivate them. To address this issue, we adopt a weakly supervised learning model, which jointly learns to focus on relevant parts of a document according to the context along with a classifier for the target categories. Originated from the weighted multiple-instance regression (MIR) framework, the modellearns decomposable document vectors for each individual category and thus overcomesthe representational bottleneck in previous methods due to a fixed-length document vector. During prediction, the estimated relevance or saliency weights explicitly capture the contribution of each sentence to the predicted rating, thus offering an explanation of the rating. Our model achieves state-of-the-art performance on multi-aspect sentiment analysis, improving over several baselines. Moreover, the predicted saliency weights are close to human estimates obtained by crowdsourcing and increase the performance of lexical and topical features for review segmentation and summarization.
PDF

