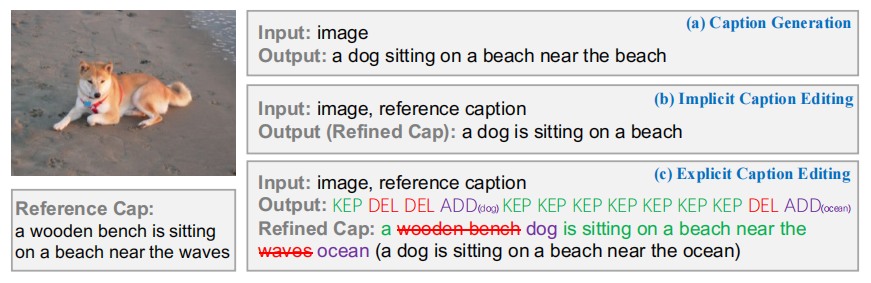
Explicit Image Caption Editing
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption. However, all existing caption editing works are implicit models, ie, they directly produce the refined captions without explicit connections to the reference captions. In this paper, we introduce a new task: Explicit Caption Editing (ECE). ECE models explicitly generate a sequence of edit operations, and this edit operation sequence can translate the reference caption into a refined one. Compared to the implicit editing, ECE has multiple advantages: 1) Explainable: it can trace the whole editing path. 2) Editing Efficient: it only needs to modify a few words. 3) Human-like: it resembles the way that humans perform caption editing, and tries to keep original sentence structures. To solve this new task, we propose the first ECE model: TIger. TIger is a non-autoregressive transformer-based model, consisting of three modules: Tagger_del, Tagger_add, and Inserter. Specifically, Tagger_del decides whether each word should be preserved or not, Tagger_add decides where to add new words, and Inserter predicts the specific word for adding. To further facilitate ECE research, we propose two new ECE benchmarks by re-organizing two existing datasets, dubbed COCO-EE and Flickr30K-EE, respectively. Extensive ablations on both two benchmarks have demonstrated the effectiveness of TIger.
PDF Abstract
 MS COCO
MS COCO
 Flickr30k
Flickr30k
 e-SNLI-VE
e-SNLI-VE
