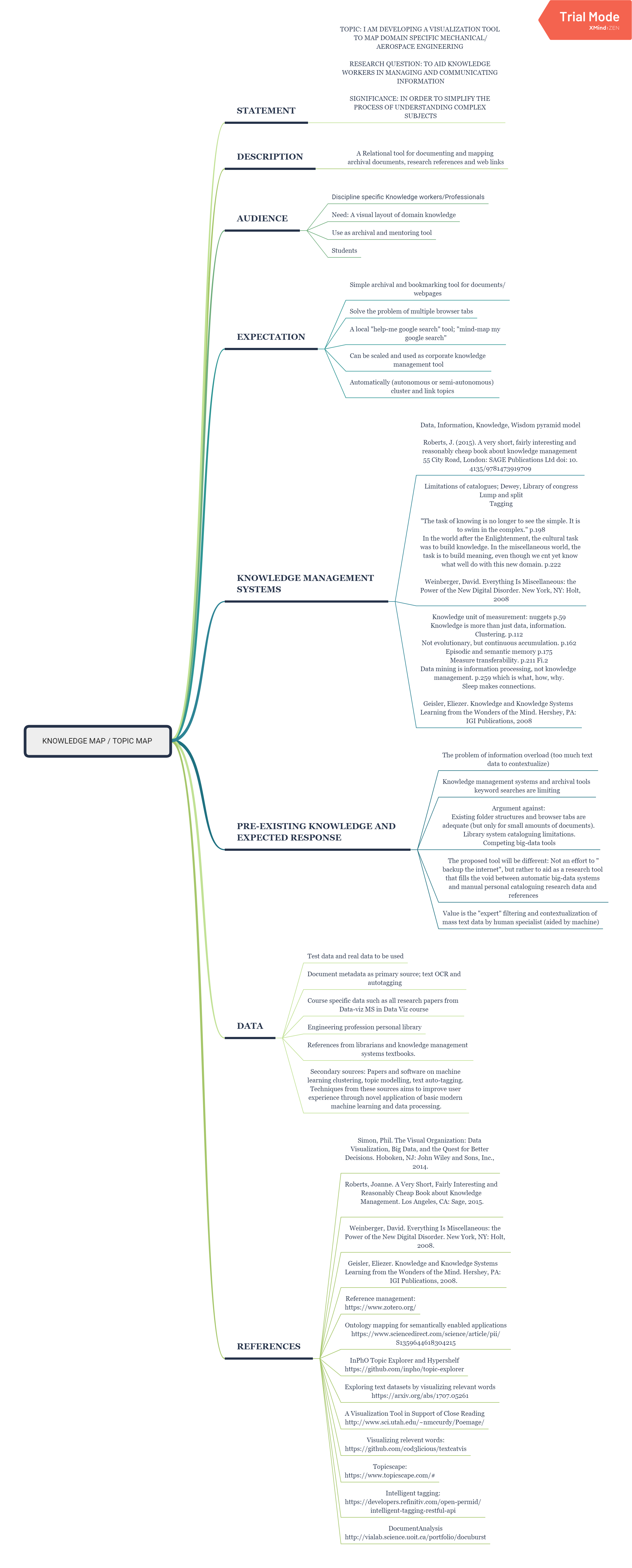
Exploring text datasets by visualizing relevant words
When working with a new dataset, it is important to first explore and familiarize oneself with it, before applying any advanced machine learning algorithms. However, to the best of our knowledge, no tools exist that quickly and reliably give insight into the contents of a selection of documents with respect to what distinguishes them from other documents belonging to different categories. In this paper we propose to extract `relevant words' from a collection of texts, which summarize the contents of documents belonging to a certain class (or discovered cluster in the case of unlabeled datasets), and visualize them in word clouds to allow for a survey of salient features at a glance. We compare three methods for extracting relevant words and demonstrate the usefulness of the resulting word clouds by providing an overview of the classes contained in a dataset of scientific publications as well as by discovering trending topics from recent New York Times article snippets.
PDF Abstract
