Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
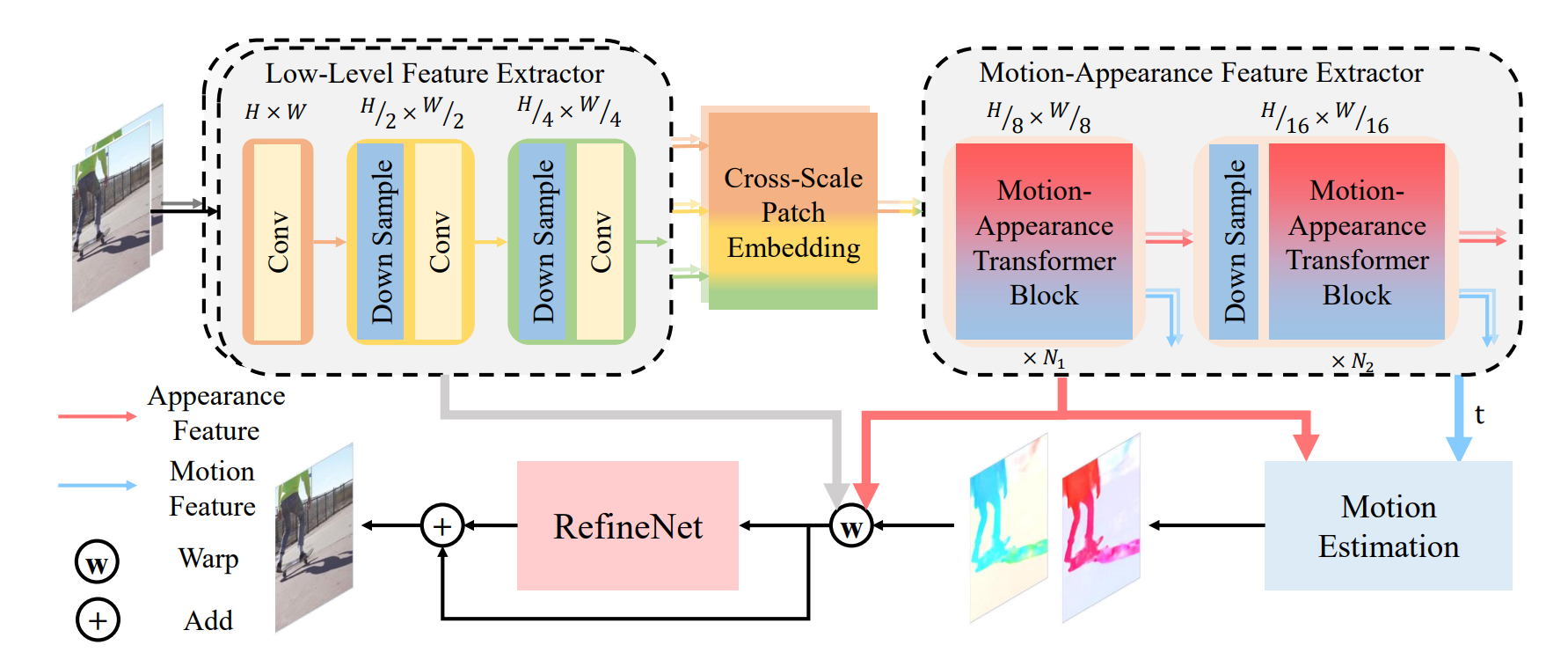
Effectively extracting inter-frame motion and appearance information is important for video frame interpolation (VFI). Previous works either extract both types of information in a mixed way or elaborate separate modules for each type of information, which lead to representation ambiguity and low efficiency. In this paper, we propose a novel module to explicitly extract motion and appearance information via a unifying operation. Specifically, we rethink the information process in inter-frame attention and reuse its attention map for both appearance feature enhancement and motion information extraction. Furthermore, for efficient VFI, our proposed module could be seamlessly integrated into a hybrid CNN and Transformer architecture. This hybrid pipeline can alleviate the computational complexity of inter-frame attention as well as preserve detailed low-level structure information. Experimental results demonstrate that, for both fixed- and arbitrary-timestep interpolation, our method achieves state-of-the-art performance on various datasets. Meanwhile, our approach enjoys a lighter computation overhead over models with close performance. The source code and models are available at https://github.com/MCG-NJU/EMA-VFI.
PDF Abstract CVPR 2023 PDF CVPR 2023 AbstractCode


 UCF101
UCF101
 Middlebury
Middlebury
 Vimeo90K
Vimeo90K
 X4K1000FPS
X4K1000FPS
 MSU Video Frame Interpolation
MSU Video Frame Interpolation
Results from the Paper
 Ranked #1 on
Video Frame Interpolation
on MSU Video Frame Interpolation
(PSNR metric)
Ranked #1 on
Video Frame Interpolation
on MSU Video Frame Interpolation
(PSNR metric)
