Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices
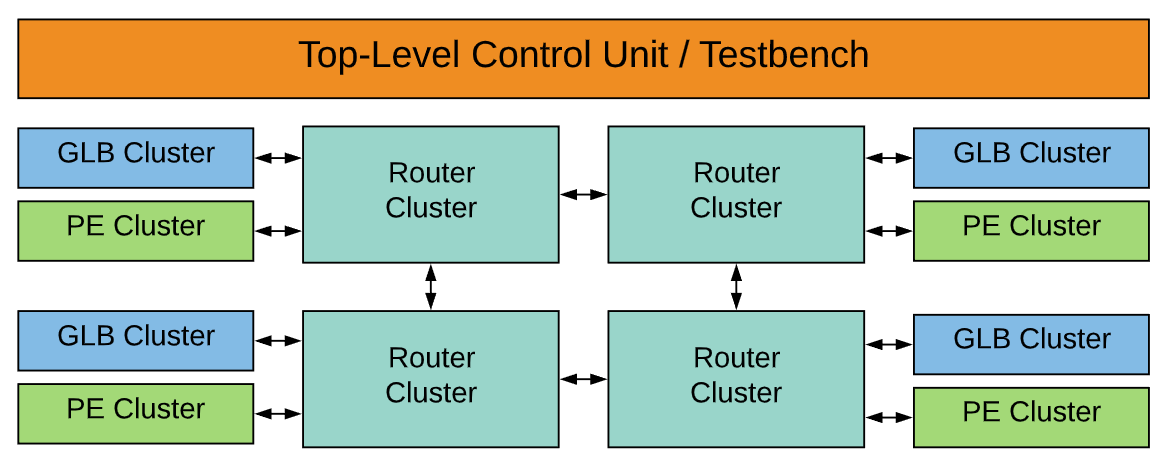
A recent trend in DNN development is to extend the reach of deep learning applications to platforms that are more resource and energy constrained, e.g., mobile devices. These endeavors aim to reduce the DNN model size and improve the hardware processing efficiency, and have resulted in DNNs that are much more compact in their structures and/or have high data sparsity. These compact or sparse models are different from the traditional large ones in that there is much more variation in their layer shapes and sizes, and often require specialized hardware to exploit sparsity for performance improvement. Thus, many DNN accelerators designed for large DNNs do not perform well on these models. In this work, we present Eyeriss v2, a DNN accelerator architecture designed for running compact and sparse DNNs. To deal with the widely varying layer shapes and sizes, it introduces a highly flexible on-chip network, called hierarchical mesh, that can adapt to the different amounts of data reuse and bandwidth requirements of different data types, which improves the utilization of the computation resources. Furthermore, Eyeriss v2 can process sparse data directly in the compressed domain for both weights and activations, and therefore is able to improve both processing speed and energy efficiency with sparse models. Overall, with sparse MobileNet, Eyeriss v2 in a 65nm CMOS process achieves a throughput of 1470.6 inferences/sec and 2560.3 inferences/J at a batch size of 1, which is 12.6x faster and 2.5x more energy efficient than the original Eyeriss running MobileNet. We also present an analysis methodology called Eyexam that provides a systematic way of understanding the performance limits for DNN processors as a function of specific characteristics of the DNN model and accelerator design; it applies these characteristics as sequential steps to increasingly tighten the bound on the performance limits.
PDF Abstract