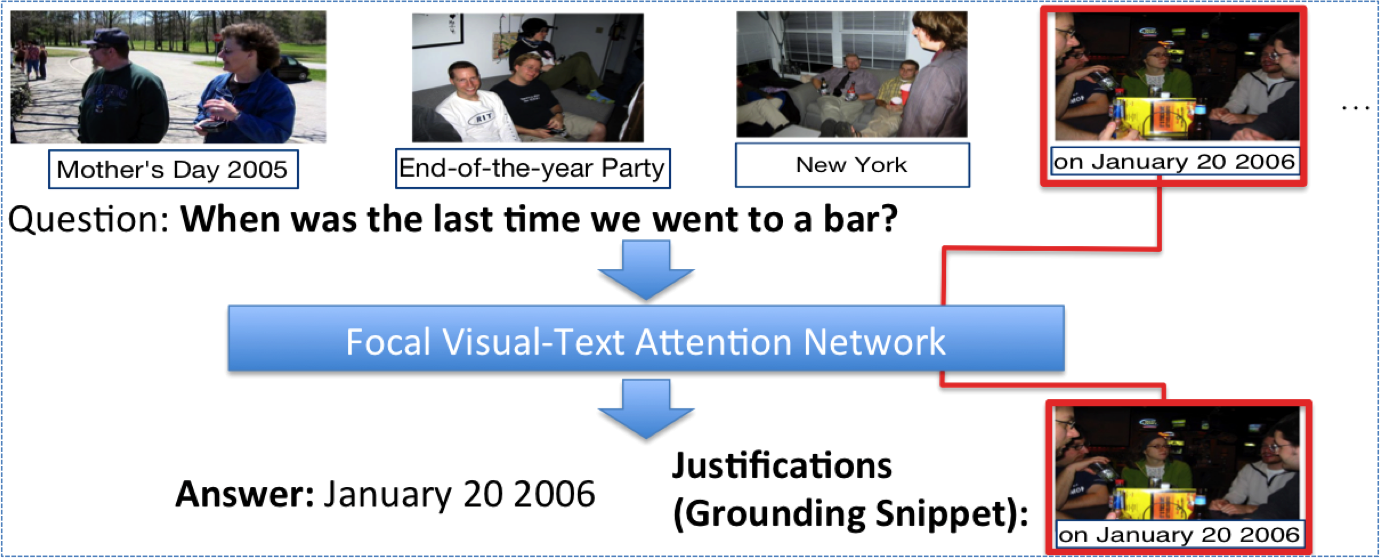
Focal Visual-Text Attention for Memex Question Answering
Recent insights on language and vision with neural networks have been successfully applied to simple single-image visual question answering. However, to tackle real-life question answering problems on multimedia collections such as personal photo albums, we have to look at whole collections with sequences of photos. This paper proposes a new multimodal MemexQA task: given a sequence of photos from a user, the goal is to automatically answer questions that help users recover their memory about an event captured in these photos. In addition to a text answer, a few grounding photos are also given to justify the answer. The grounding photos are necessary as they help users quickly verifying the answer. Towards solving the task, we 1) present the MemexQA dataset, the first publicly available multimodal question answering dataset consisting of real personal photo albums; 2) propose an end-to-end trainable network that makes use of a hierarchical process to dynamically determine what media and what time to focus on in the sequential data to answer the question. Experimental results on the MemexQA dataset demonstrate that our model outperforms strong baselines and yields the most relevant grounding photos on this challenging task.
PDF AbstractCode




Datasets
 MemexQA
MemexQA

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Memex Question Answering | MemexQA | FVTA | Accuracy | 0.357 | # 1 |
