Frozen CLIP Models are Efficient Video Learners
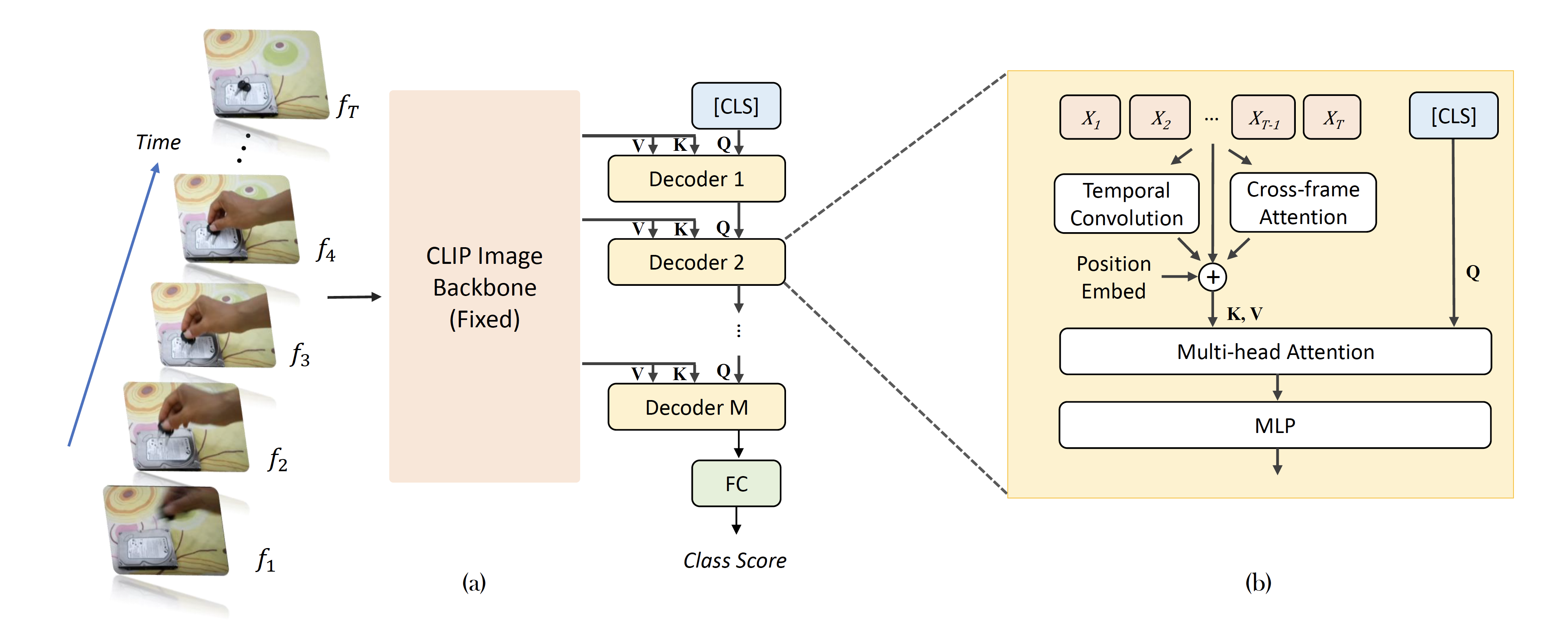
Video recognition has been dominated by the end-to-end learning paradigm -- first initializing a video recognition model with weights of a pretrained image model and then conducting end-to-end training on videos. This enables the video network to benefit from the pretrained image model. However, this requires substantial computation and memory resources for finetuning on videos and the alternative of directly using pretrained image features without finetuning the image backbone leads to subpar results. Fortunately, recent advances in Contrastive Vision-Language Pre-training (CLIP) pave the way for a new route for visual recognition tasks. Pretrained on large open-vocabulary image-text pair data, these models learn powerful visual representations with rich semantics. In this paper, we present Efficient Video Learning (EVL) -- an efficient framework for directly training high-quality video recognition models with frozen CLIP features. Specifically, we employ a lightweight Transformer decoder and learn a query token to dynamically collect frame-level spatial features from the CLIP image encoder. Furthermore, we adopt a local temporal module in each decoder layer to discover temporal clues from adjacent frames and their attention maps. We show that despite being efficient to train with a frozen backbone, our models learn high quality video representations on a variety of video recognition datasets. Code is available at https://github.com/OpenGVLab/efficient-video-recognition.
PDF Abstract


Datasets
 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
Results from the Paper
 Ranked #26 on
Action Classification
on Kinetics-400
(using extra training data)
Ranked #26 on
Action Classification
on Kinetics-400
(using extra training data)
