Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
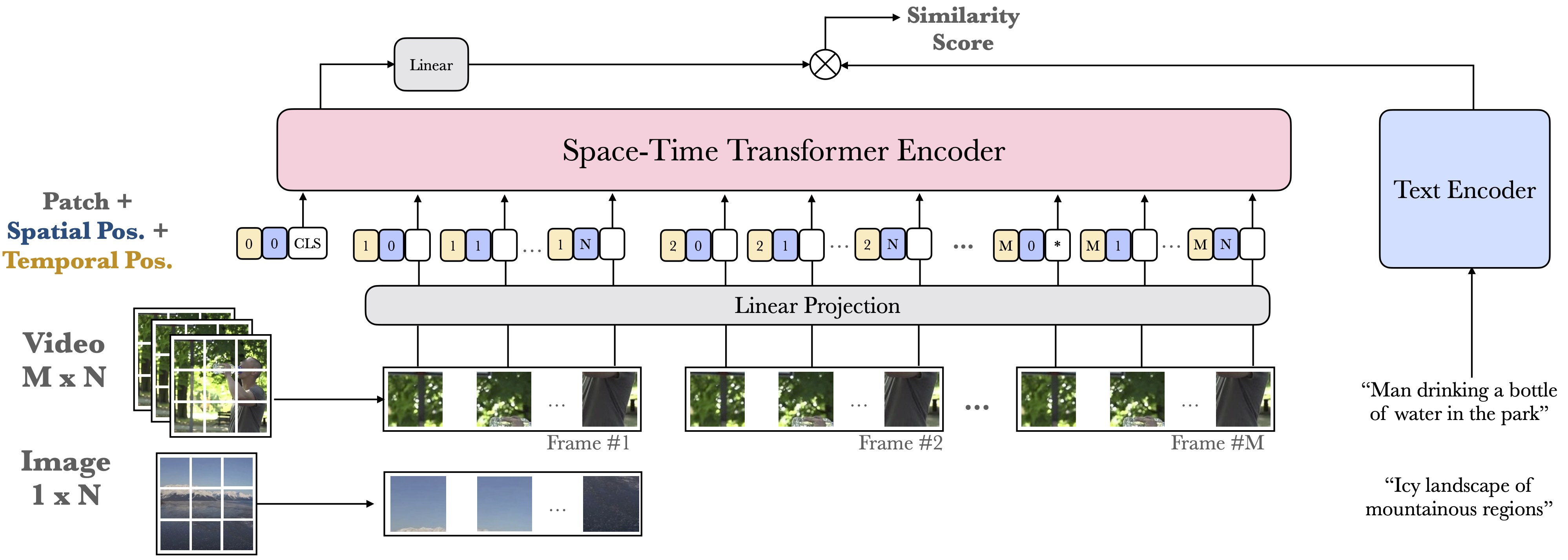
Our objective in this work is video-text retrieval - in particular a joint embedding that enables efficient text-to-video retrieval. The challenges in this area include the design of the visual architecture and the nature of the training data, in that the available large scale video-text training datasets, such as HowTo100M, are noisy and hence competitive performance is achieved only at scale through large amounts of compute. We address both these challenges in this paper. We propose an end-to-end trainable model that is designed to take advantage of both large-scale image and video captioning datasets. Our model is an adaptation and extension of the recent ViT and Timesformer architectures, and consists of attention in both space and time. The model is flexible and can be trained on both image and video text datasets, either independently or in conjunction. It is trained with a curriculum learning schedule that begins by treating images as 'frozen' snapshots of video, and then gradually learns to attend to increasing temporal context when trained on video datasets. We also provide a new video-text pretraining dataset WebVid-2M, comprised of over two million videos with weak captions scraped from the internet. Despite training on datasets that are an order of magnitude smaller, we show that this approach yields state-of-the-art results on standard downstream video-retrieval benchmarks including MSR-VTT, MSVD, DiDeMo and LSMDC.
PDF Abstract ICCV 2021 PDF ICCV 2021 AbstractCode


 WebVid
WebVid
 MS COCO
MS COCO
 Kinetics
Kinetics
 Flickr30k
Flickr30k
 MSR-VTT
MSR-VTT
 Conceptual Captions
Conceptual Captions
 MSVD
MSVD
 HowTo100M
HowTo100M
 DiDeMo
DiDeMo
 COCO Captions
COCO Captions
 LSMDC
LSMDC
Results from the Paper
 Ranked #4 on
Video Retrieval
on QuerYD
(using extra training data)
Ranked #4 on
Video Retrieval
on QuerYD
(using extra training data)
