Fully Decoupled Neural Network Learning Using Delayed Gradients
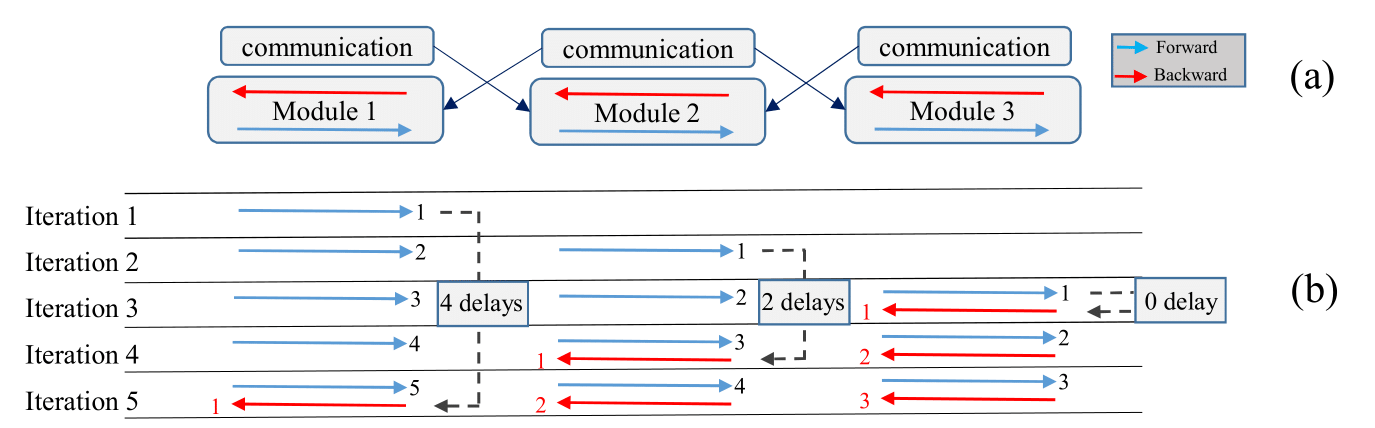
Training neural networks with back-propagation (BP) requires a sequential passing of activations and gradients, which forces the network modules to work in a synchronous fashion. This has been recognized as the lockings (i.e., the forward, backward and update lockings) inherited from the BP. In this paper, we propose a fully decoupled training scheme using delayed gradients (FDG) to break all these lockings. The FDG splits a neural network into multiple modules and trains them independently and asynchronously using different workers (e.g., GPUs). We also introduce a gradient shrinking process to reduce the stale gradient effect caused by the delayed gradients. In addition, we prove that the proposed FDG algorithm guarantees a statistical convergence during training. Experiments are conducted by training deep convolutional neural networks to perform classification tasks on benchmark datasets, showing comparable or better results against the state-of-the-art methods as well as the BP in terms of both generalization and acceleration abilities. In particular, we show that the FDG is also able to train very wide networks (e.g., WRN-28-10) and extremely deep networks (e.g., ResNet-1202). Code is available at https://github.com/ZHUANGHP/FDG.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
