Gendered Pronoun Resolution using BERT and an extractive question answering formulation
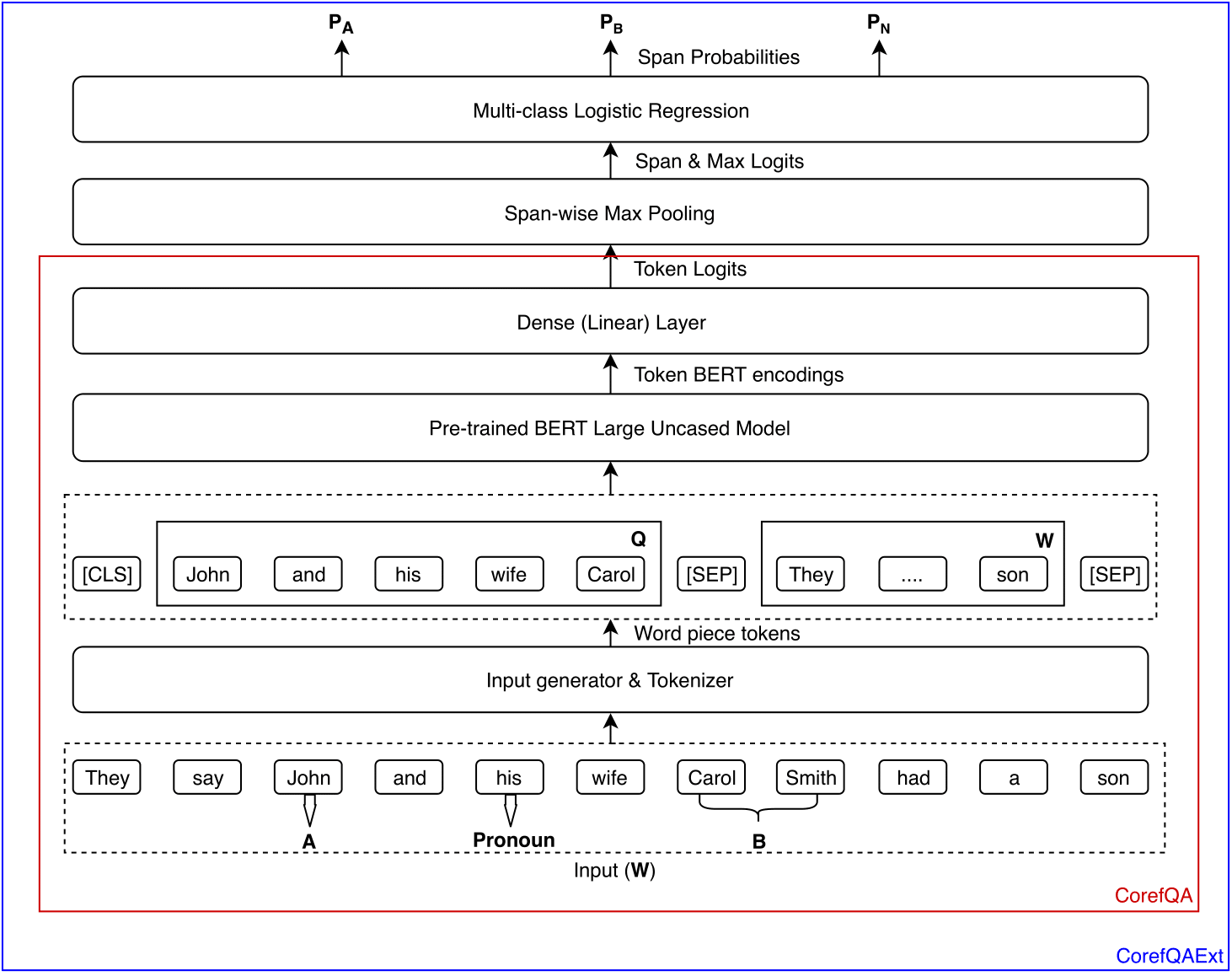
The resolution of ambiguous pronouns is a longstanding challenge in Natural Language Understanding. Recent studies have suggested gender bias among state-of-the-art coreference resolution systems. As an example, Google AI Language team recently released a gender-balanced dataset and showed that performance of these coreference resolvers is significantly limited on the dataset. In this paper, we propose an extractive question answering (QA) formulation of pronoun resolution task that overcomes this limitation and shows much lower gender bias (0.99) on their dataset. This system uses fine-tuned representations from the pre-trained BERT model and outperforms the existing baseline by a significant margin (22.2% absolute improvement in F1 score) without using any hand-engineered features. This QA framework is equally performant even without the knowledge of the candidate antecedents of the pronoun. An ensemble of QA and BERT-based multiple choice and sequence classification models further improves the F1 (23.3% absolute improvement upon the baseline). This ensemble model was submitted to the shared task for the 1st ACL workshop on Gender Bias for Natural Language Processing. It ranked 9th on the final official leaderboard. Source code is available at https://github.com/rakeshchada/corefqa
PDF Abstract WS 2019 PDF WS 2019 Abstract


 WSC
WSC
 SWAG
SWAG
 GAP Coreference Dataset
GAP Coreference Dataset

