GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
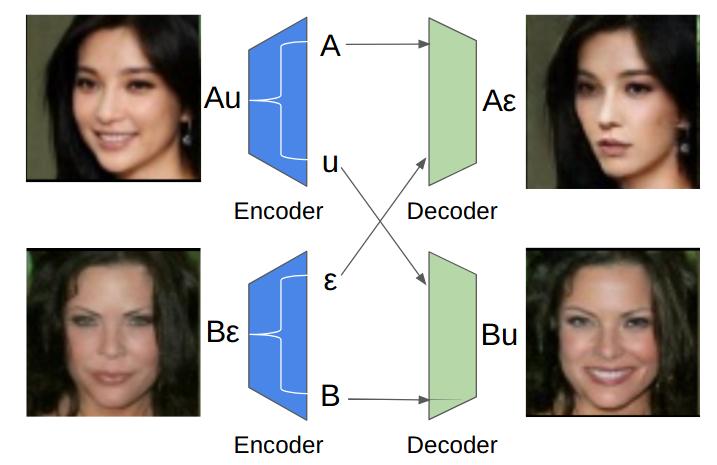
Object Transfiguration replaces an object in an image with another object from a second image. For example it can perform tasks like "putting exactly those eyeglasses from image A on the nose of the person in image B". Usage of exemplar images allows more precise specification of desired modifications and improves the diversity of conditional image generation. However, previous methods that rely on feature space operations, require paired data and/or appearance models for training or disentangling objects from background. In this work, we propose a model that can learn object transfiguration from two unpaired sets of images: one set containing images that "have" that kind of object, and the other set being the opposite, with the mild constraint that the objects be located approximately at the same place. For example, the training data can be one set of reference face images that have eyeglasses, and another set of images that have not, both of which spatially aligned by face landmarks. Despite the weak 0/1 labels, our model can learn an "eyeglasses" subspace that contain multiple representatives of different types of glasses. Consequently, we can perform fine-grained control of generated images, like swapping the glasses in two images by swapping the projected components in the "eyeglasses" subspace, to create novel images of people wearing eyeglasses. Overall, our deterministic generative model learns disentangled attribute subspaces from weakly labeled data by adversarial training. Experiments on CelebA and Multi-PIE datasets validate the effectiveness of the proposed model on real world data, in generating images with specified eyeglasses, smiling, hair styles, and lighting conditions etc. The code is available online.
PDF Abstract




 CelebA
CelebA
 WIDER FACE
WIDER FACE
