Generalization and Exploration via Randomized Value Functions
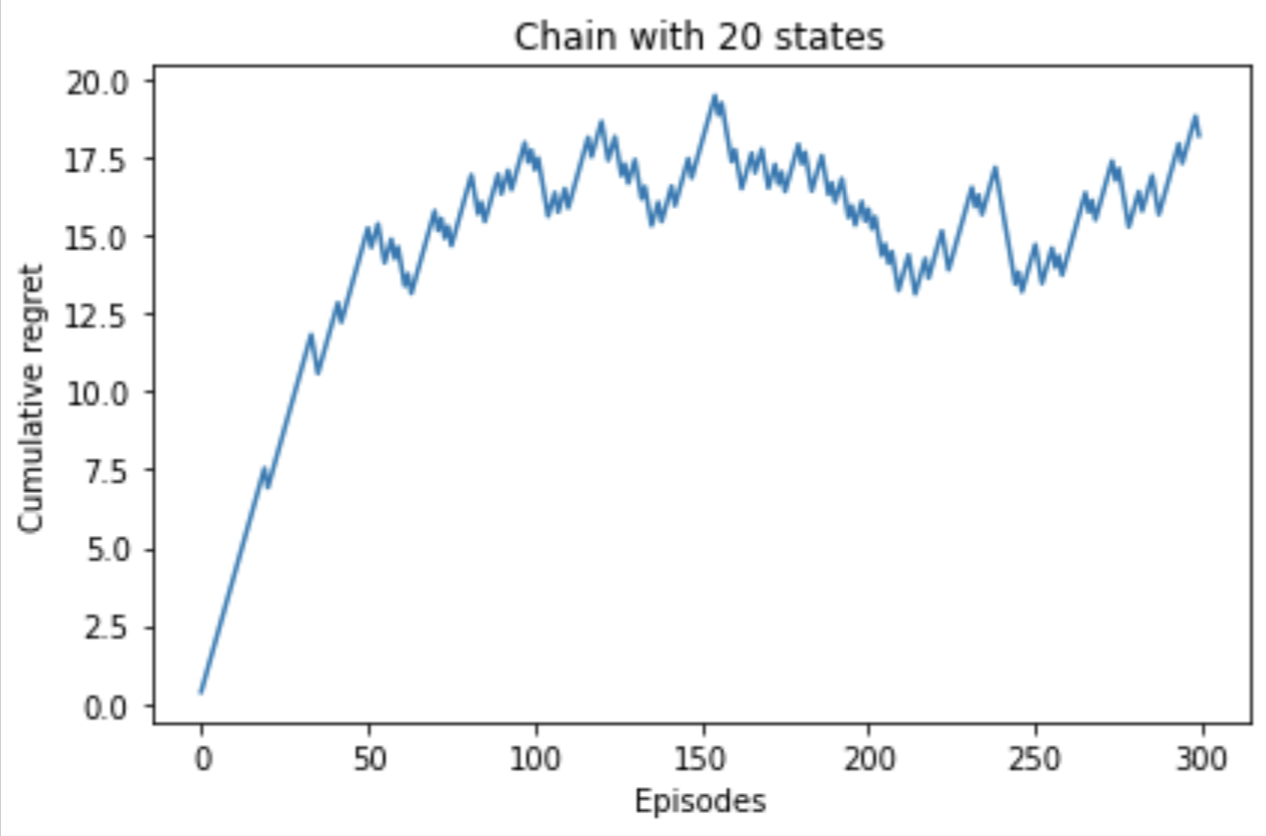
We propose randomized least-squares value iteration (RLSVI) -- a new reinforcement learning algorithm designed to explore and generalize efficiently via linearly parameterized value functions. We explain why versions of least-squares value iteration that use Boltzmann or epsilon-greedy exploration can be highly inefficient, and we present computational results that demonstrate dramatic efficiency gains enjoyed by RLSVI. Further, we establish an upper bound on the expected regret of RLSVI that demonstrates near-optimality in a tabula rasa learning context. More broadly, our results suggest that randomized value functions offer a promising approach to tackling a critical challenge in reinforcement learning: synthesizing efficient exploration and effective generalization.
PDF Abstract Colab
Colab


