Test-time Adaptation with Slot-Centric Models
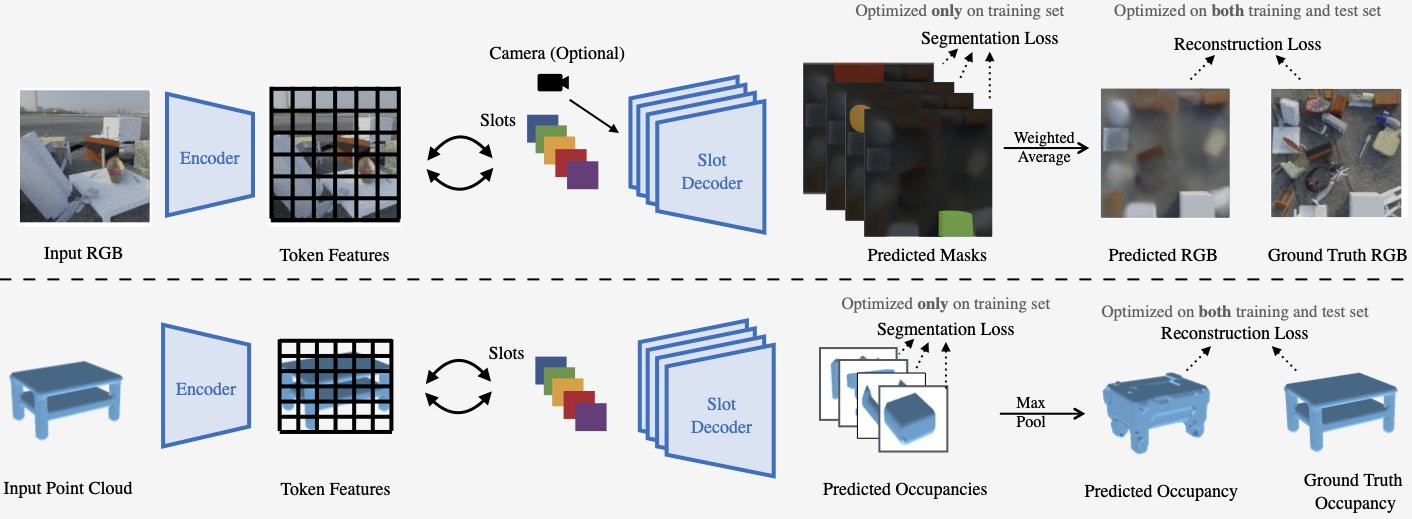
Current visual detectors, though impressive within their training distribution, often fail to parse out-of-distribution scenes into their constituent entities. Recent test-time adaptation methods use auxiliary self-supervised losses to adapt the network parameters to each test example independently and have shown promising results towards generalization outside the training distribution for the task of image classification. In our work, we find evidence that these losses are insufficient for the task of scene decomposition, without also considering architectural inductive biases. Recent slot-centric generative models attempt to decompose scenes into entities in a self-supervised manner by reconstructing pixels. Drawing upon these two lines of work, we propose Slot-TTA, a semi-supervised slot-centric scene decomposition model that at test time is adapted per scene through gradient descent on reconstruction or cross-view synthesis objectives. We evaluate Slot-TTA across multiple input modalities, images or 3D point clouds, and show substantial out-of-distribution performance improvements against state-of-the-art supervised feed-forward detectors, and alternative test-time adaptation methods.
PDF Abstract






 MS COCO
MS COCO
 ShapeNet
ShapeNet
 CLEVR
CLEVR
 PartNet
PartNet
 ClevrTex
ClevrTex
