Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in Videos
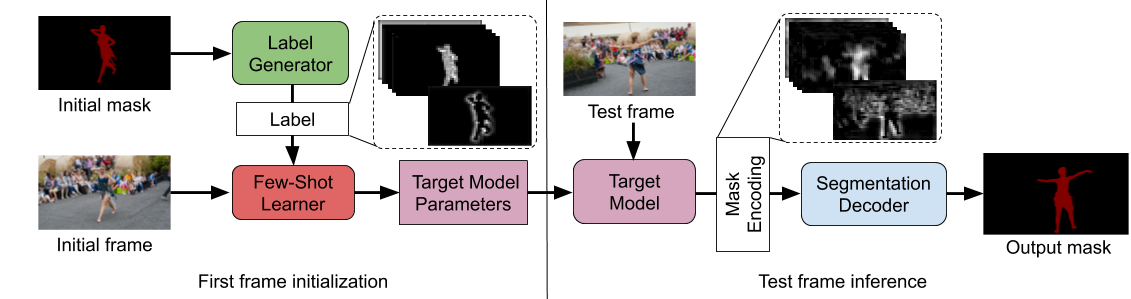
Segmenting objects in videos is a fundamental computer vision task. The current deep learning based paradigm offers a powerful, but data-hungry solution. However, current datasets are limited by the cost and human effort of annotating object masks in videos. This effectively limits the performance and generalization capabilities of existing video segmentation methods. To address this issue, we explore weaker form of bounding box annotations. We introduce a method for generating segmentation masks from per-frame bounding box annotations in videos. To this end, we propose a spatio-temporal aggregation module that effectively mines consistencies in the object and background appearance across multiple frames. We use our resulting accurate masks for weakly supervised training of video object segmentation (VOS) networks. We generate segmentation masks for large scale tracking datasets, using only their bounding box annotations. The additional data provides substantially better generalization performance leading to state-of-the-art results in both the VOS and more challenging tracking domain.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract



 DAVIS 2017
DAVIS 2017
 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
 YouTube-VOS 2018
YouTube-VOS 2018
