Generative Compositional Augmentations for Scene Graph Prediction
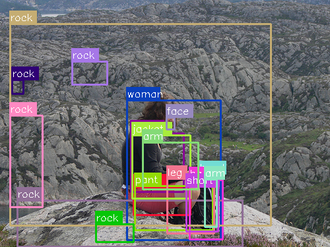
Inferring objects and their relationships from an image in the form of a scene graph is useful in many applications at the intersection of vision and language. We consider a challenging problem of compositional generalization that emerges in this task due to a long tail data distribution. Current scene graph generation models are trained on a tiny fraction of the distribution corresponding to the most frequent compositions, e.g. <cup, on, table>. However, test images might contain zero- and few-shot compositions of objects and relationships, e.g. <cup, on, surfboard>. Despite each of the object categories and the predicate (e.g. 'on') being frequent in the training data, the models often fail to properly understand such unseen or rare compositions. To improve generalization, it is natural to attempt increasing the diversity of the training distribution. However, in the graph domain this is non-trivial. To that end, we propose a method to synthesize rare yet plausible scene graphs by perturbing real ones. We then propose and empirically study a model based on conditional generative adversarial networks (GANs) that allows us to generate visual features of perturbed scene graphs and learn from them in a joint fashion. When evaluated on the Visual Genome dataset, our approach yields marginal, but consistent improvements in zero- and few-shot metrics. We analyze the limitations of our approach indicating promising directions for future research.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract


 Visual Genome
Visual Genome
 VRD
VRD
