Generative Modelling for Controllable Audio Synthesis of Expressive Piano Performance
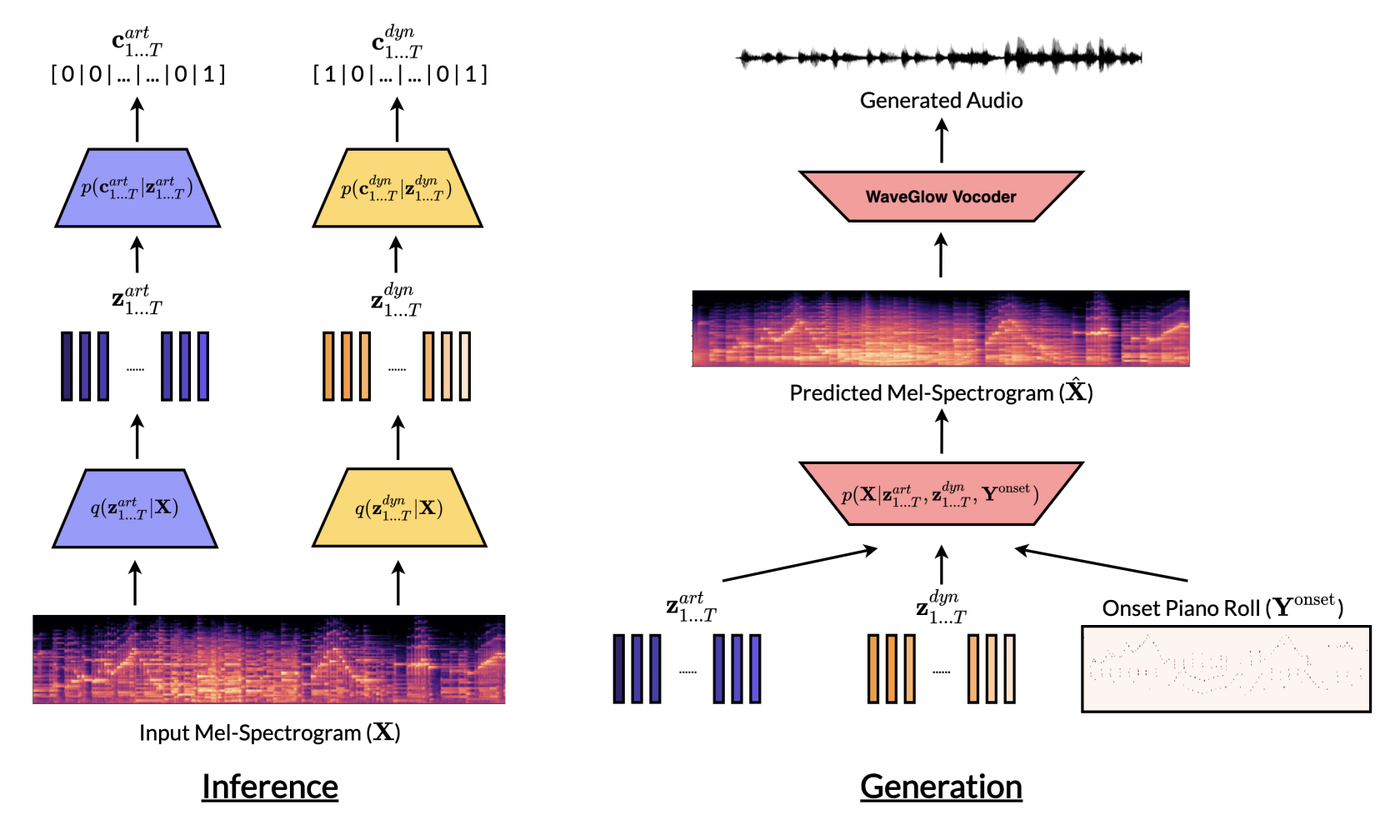
We present a controllable neural audio synthesizer based on Gaussian Mixture Variational Autoencoders (GM-VAE), which can generate realistic piano performances in the audio domain that closely follows temporal conditions of two essential style features for piano performances: articulation and dynamics. We demonstrate how the model is able to apply fine-grained style morphing over the course of synthesizing the audio. This is based on conditions which are latent variables that can be sampled from the prior or inferred from other pieces. One of the envisioned use cases is to inspire creative and brand new interpretations for existing pieces of piano music.
PDF Abstract
Tasks

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
