Gesture-to-Gesture Translation in the Wild via Category-Independent Conditional Maps
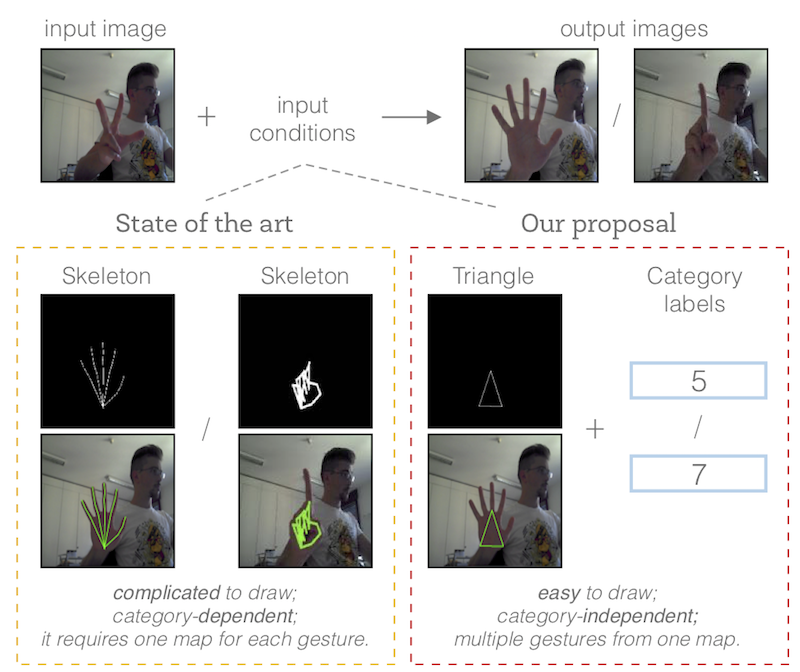
Recent works have shown Generative Adversarial Networks (GANs) to be particularly effective in image-to-image translations. However, in tasks such as body pose and hand gesture translation, existing methods usually require precise annotations, e.g. key-points or skeletons, which are time-consuming to draw. In this work, we propose a novel GAN architecture that decouples the required annotations into a category label - that specifies the gesture type - and a simple-to-draw category-independent conditional map - that expresses the location, rotation and size of the hand gesture. Our architecture synthesizes the target gesture while preserving the background context, thus effectively dealing with gesture translation in the wild. To this aim, we use an attention module and a rolling guidance approach, which loops the generated images back into the network and produces higher quality images compared to competing works. Thus, our GAN learns to generate new images from simple annotations without requiring key-points or skeleton labels. Results on two public datasets show that our method outperforms state of the art approaches both quantitatively and qualitatively. To the best of our knowledge, no work so far has addressed the gesture-to-gesture translation in the wild by requiring user-friendly annotations.
PDF Abstract

