Gimme Signals: Discriminative signal encoding for multimodal activity recognition
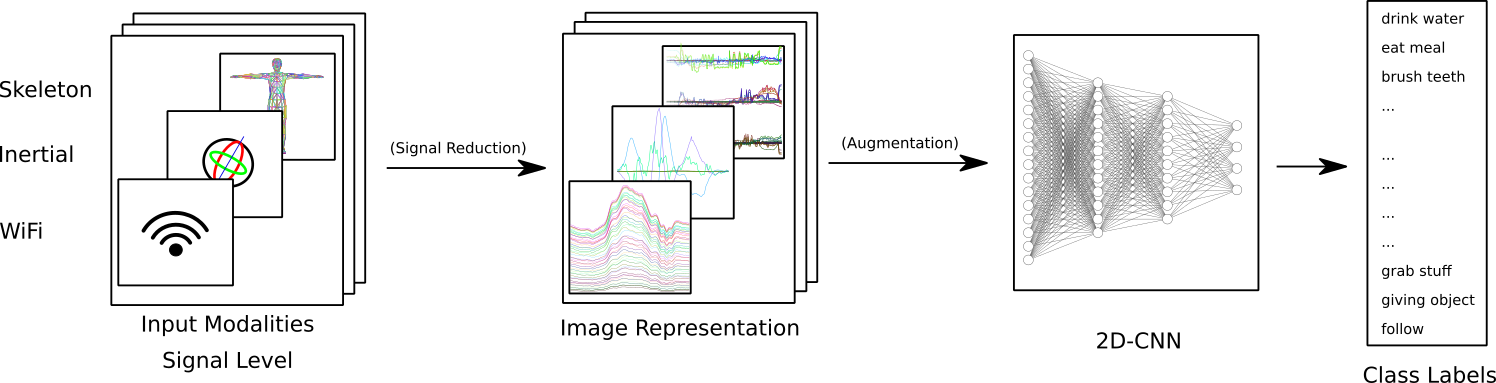
We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.
PDF Abstract



 NTU RGB+D
NTU RGB+D
 NTU RGB+D 120
NTU RGB+D 120
 UTD-MHAD
UTD-MHAD
 Simitate
Simitate

