GLAC Net: GLocal Attention Cascading Networks for Multi-image Cued Story Generation
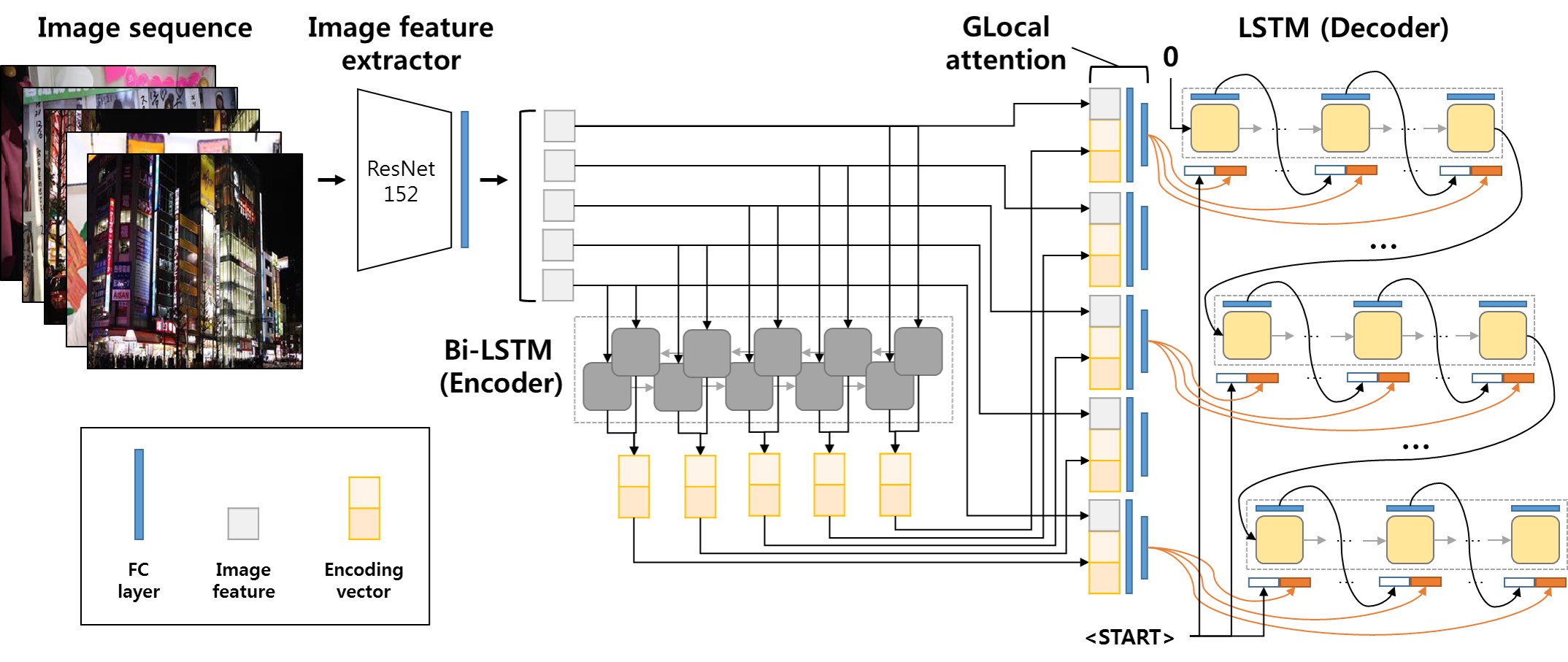
The task of multi-image cued story generation, such as visual storytelling dataset (VIST) challenge, is to compose multiple coherent sentences from a given sequence of images. The main difficulty is how to generate image-specific sentences within the context of overall images. Here we propose a deep learning network model, GLAC Net, that generates visual stories by combining global-local (glocal) attention and context cascading mechanisms. The model incorporates two levels of attention, i.e., overall encoding level and image feature level, to construct image-dependent sentences. While standard attention configuration needs a large number of parameters, the GLAC Net implements them in a very simple way via hard connections from the outputs of encoders or image features onto the sentence generators. The coherency of the generated story is further improved by conveying (cascading) the information of the previous sentence to the next sentence serially. We evaluate the performance of the GLAC Net on the visual storytelling dataset (VIST) and achieve very competitive results compared to the state-of-the-art techniques. Our code and pre-trained models are available here.
PDF Abstract


 VIST
VIST

