Glance and Focus Networks for Dynamic Visual Recognition
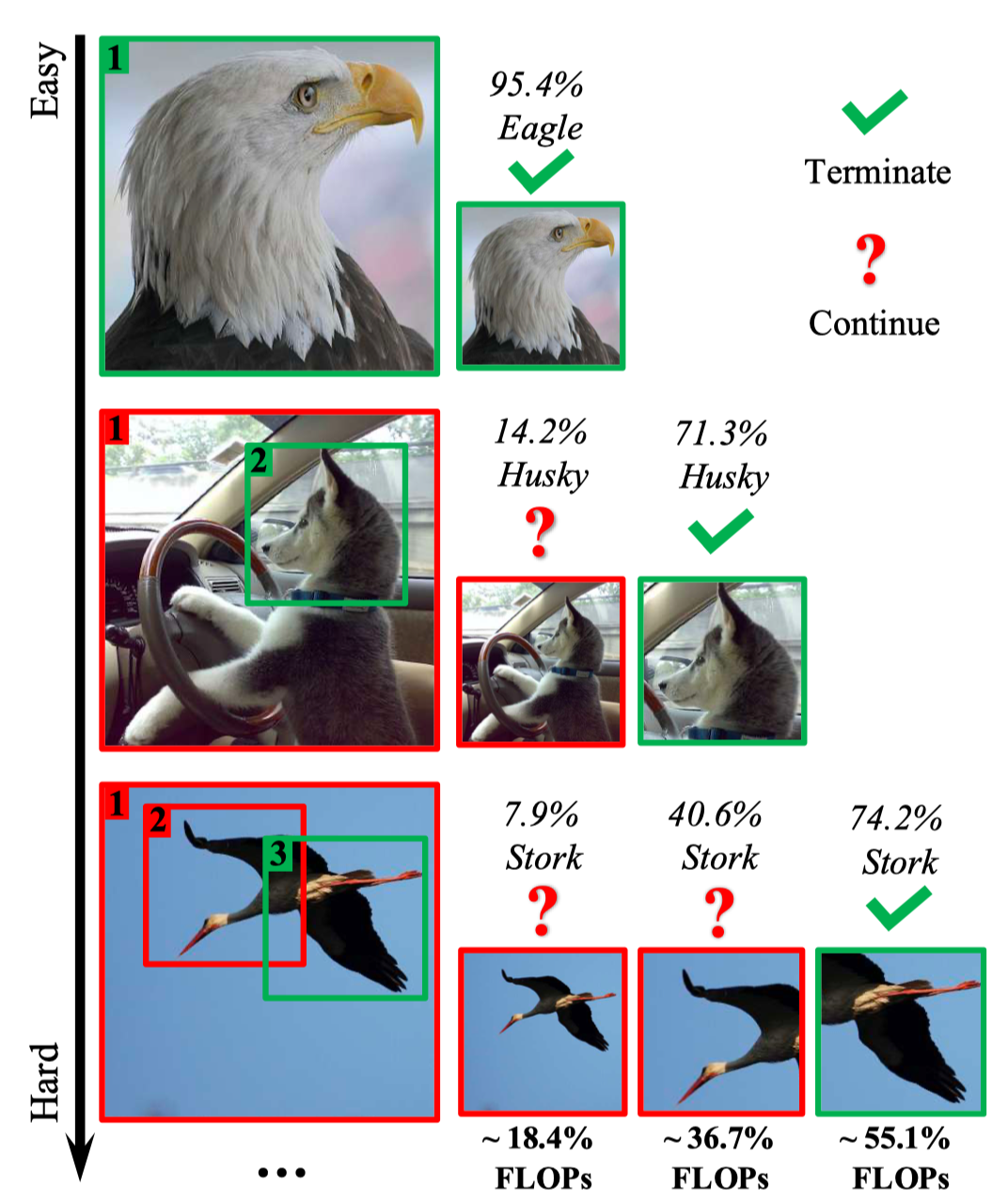
Spatial redundancy widely exists in visual recognition tasks, i.e., discriminative features in an image or video frame usually correspond to only a subset of pixels, while the remaining regions are irrelevant to the task at hand. Therefore, static models which process all the pixels with an equal amount of computation result in considerable redundancy in terms of time and space consumption. In this paper, we formulate the image recognition problem as a sequential coarse-to-fine feature learning process, mimicking the human visual system. Specifically, the proposed Glance and Focus Network (GFNet) first extracts a quick global representation of the input image at a low resolution scale, and then strategically attends to a series of salient (small) regions to learn finer features. The sequential process naturally facilitates adaptive inference at test time, as it can be terminated once the model is sufficiently confident about its prediction, avoiding further redundant computation. It is worth noting that the problem of locating discriminant regions in our model is formulated as a reinforcement learning task, thus requiring no additional manual annotations other than classification labels. GFNet is general and flexible as it is compatible with any off-the-shelf backbone models (such as MobileNets, EfficientNets and TSM), which can be conveniently deployed as the feature extractor. Extensive experiments on a variety of image classification and video recognition tasks and with various backbone models demonstrate the remarkable efficiency of our method. For example, it reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 1.3x without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.
PDF Abstract


 ImageNet
ImageNet
 Something-Something V2
Something-Something V2
 Something-Something V1
Something-Something V1
