Global-local Motion Transformer for Unsupervised Skeleton-based Action Learning
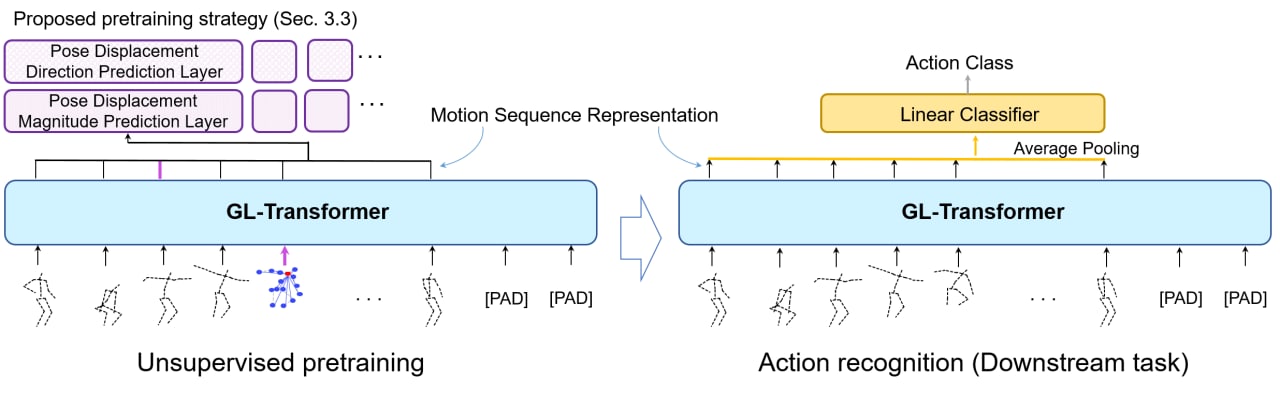
We propose a new transformer model for the task of unsupervised learning of skeleton motion sequences. The existing transformer model utilized for unsupervised skeleton-based action learning is learned the instantaneous velocity of each joint from adjacent frames without global motion information. Thus, the model has difficulties in learning the attention globally over whole-body motions and temporally distant joints. In addition, person-to-person interactions have not been considered in the model. To tackle the learning of whole-body motion, long-range temporal dynamics, and person-to-person interactions, we design a global and local attention mechanism, where, global body motions and local joint motions pay attention to each other. In addition, we propose a novel pretraining strategy, multi-interval pose displacement prediction, to learn both global and local attention in diverse time ranges. The proposed model successfully learns local dynamics of the joints and captures global context from the motion sequences. Our model outperforms state-of-the-art models by notable margins in the representative benchmarks. Codes are available at https://github.com/Boeun-Kim/GL-Transformer.
PDF Abstract
