Going Grayscale: The Road to Understanding and Improving Unlearnable Examples
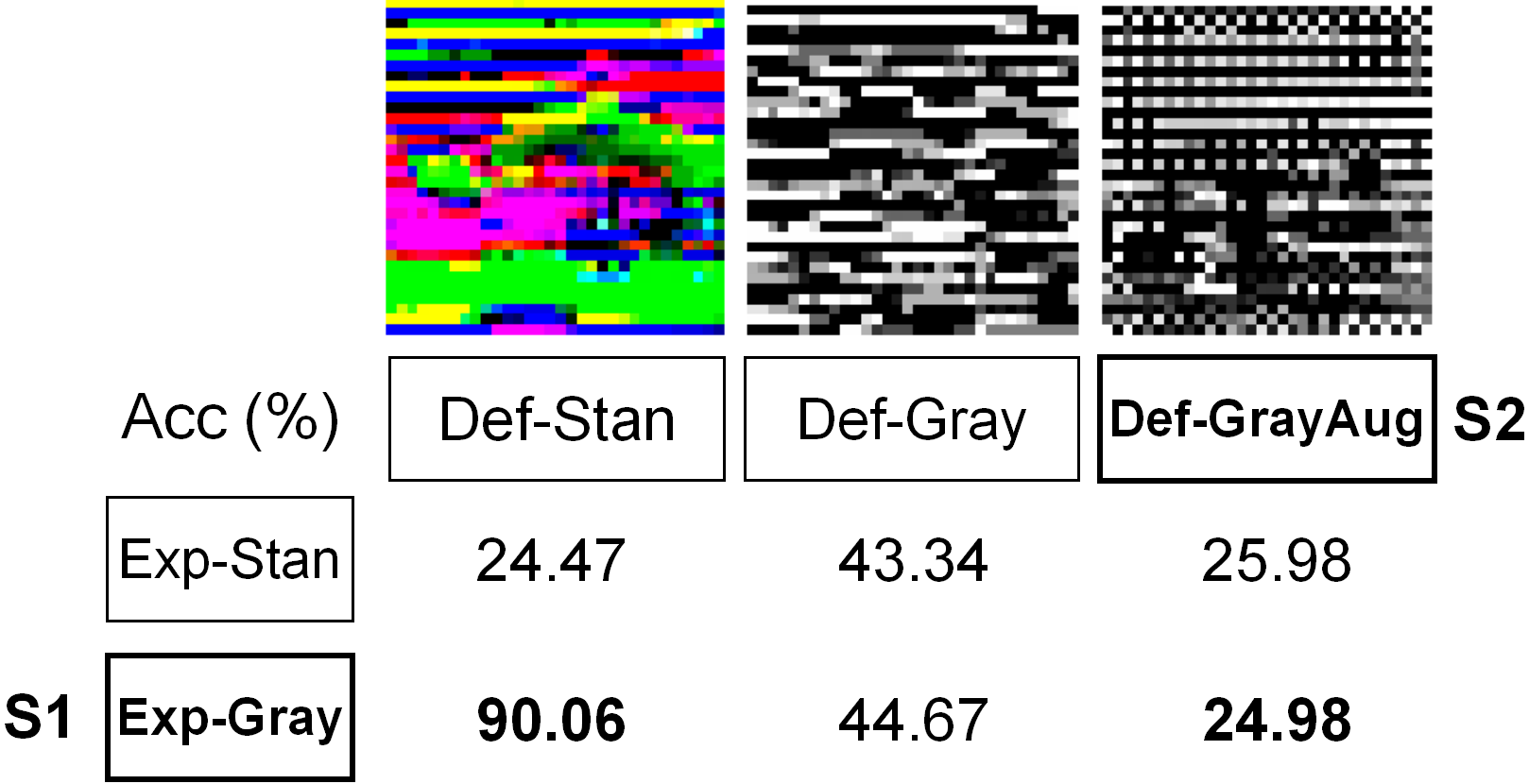
Recent work has shown that imperceptible perturbations can be applied to craft unlearnable examples (ULEs), i.e. images whose content cannot be used to improve a classifier during training. In this paper, we reveal the road that researchers should follow for understanding ULEs and improving ULEs as they were originally formulated (ULEOs). The paper makes four contributions. First, we show that ULEOs exploit color and, consequently, their effects can be mitigated by simple grayscale pre-filtering, without resorting to adversarial training. Second, we propose an extension to ULEOs, which is called ULEO-GrayAugs, that forces the generated ULEs away from channel-wise color perturbations by making use of grayscale knowledge and data augmentations during optimization. Third, we show that ULEOs generated using Multi-Layer Perceptrons (MLPs) are effective in the case of complex Convolutional Neural Network (CNN) classifiers, suggesting that CNNs suffer specific vulnerability to ULEs. Fourth, we demonstrate that when a classifier is trained on ULEOs, adversarial training will prevent a drop in accuracy measured both on clean images and on adversarial images. Taken together, our contributions represent a substantial advance in the state of art of unlearnable examples, but also reveal important characteristics of their behavior that must be better understood in order to achieve further improvements.
PDF Abstract
 ImageNet
ImageNet
