
Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
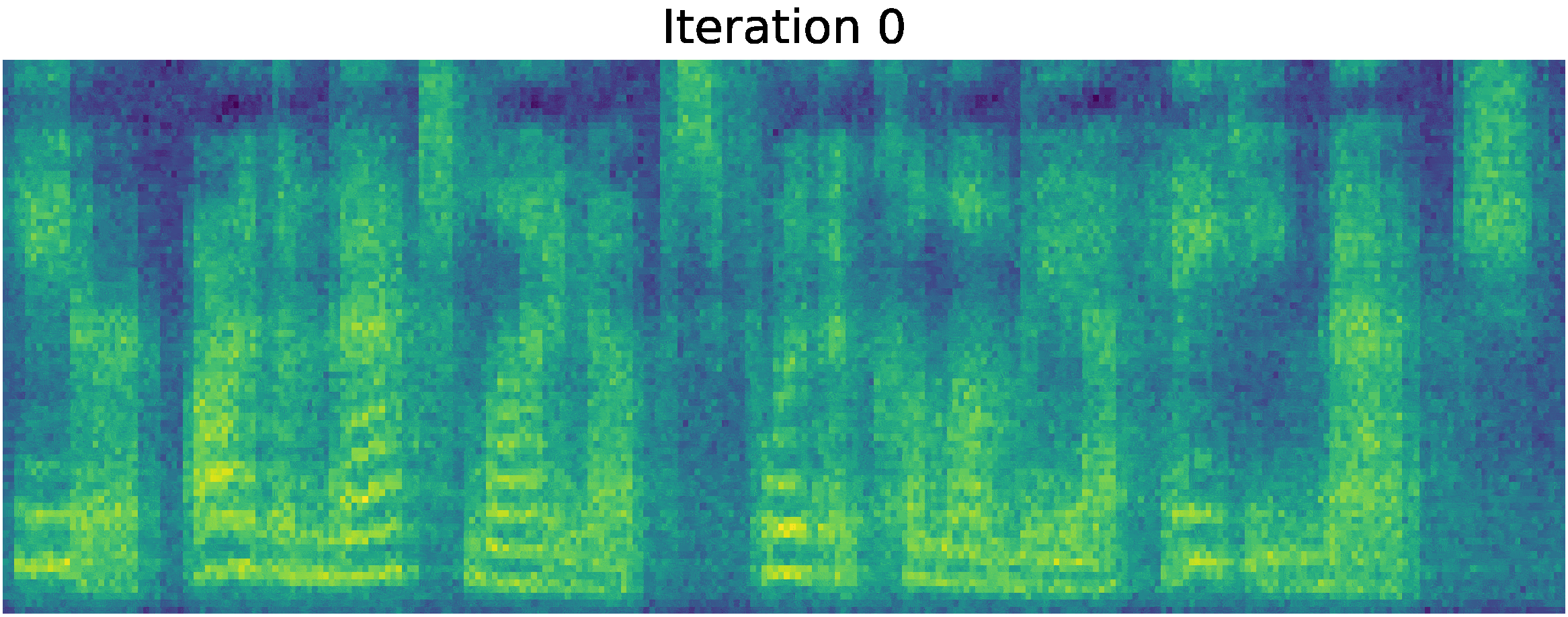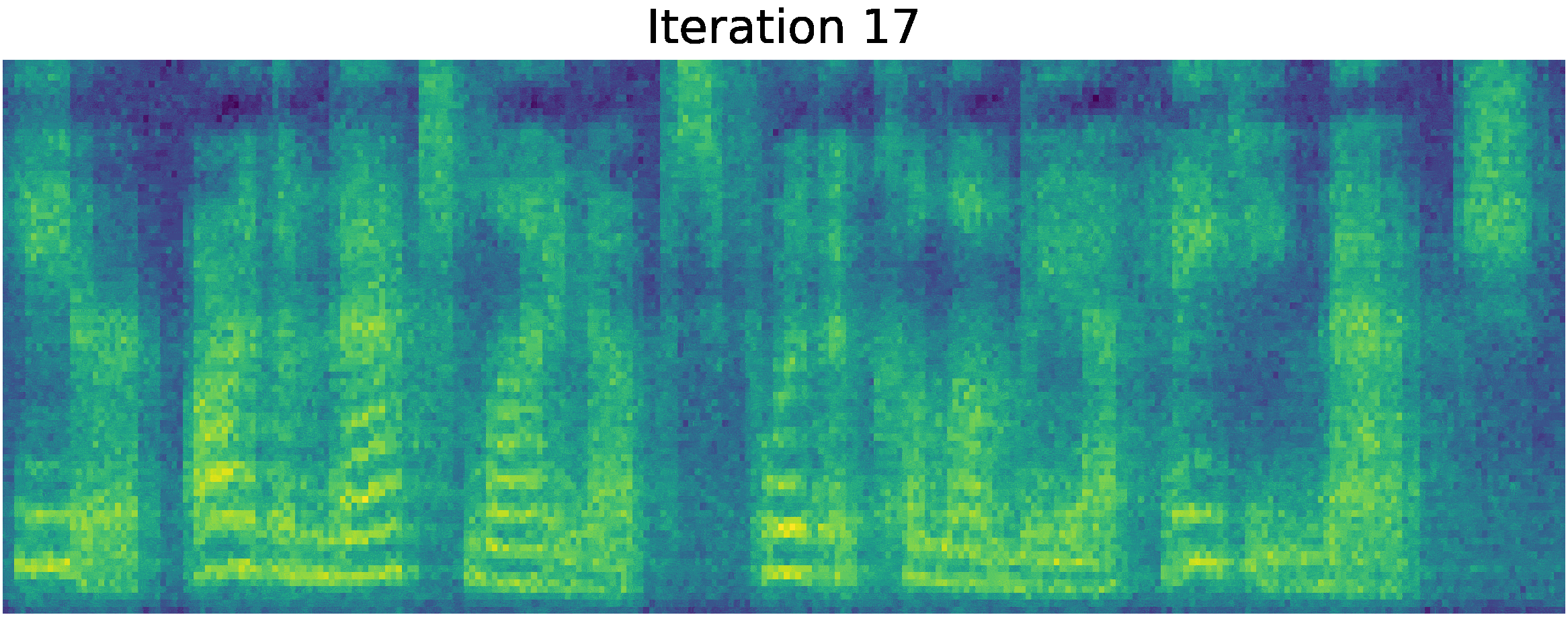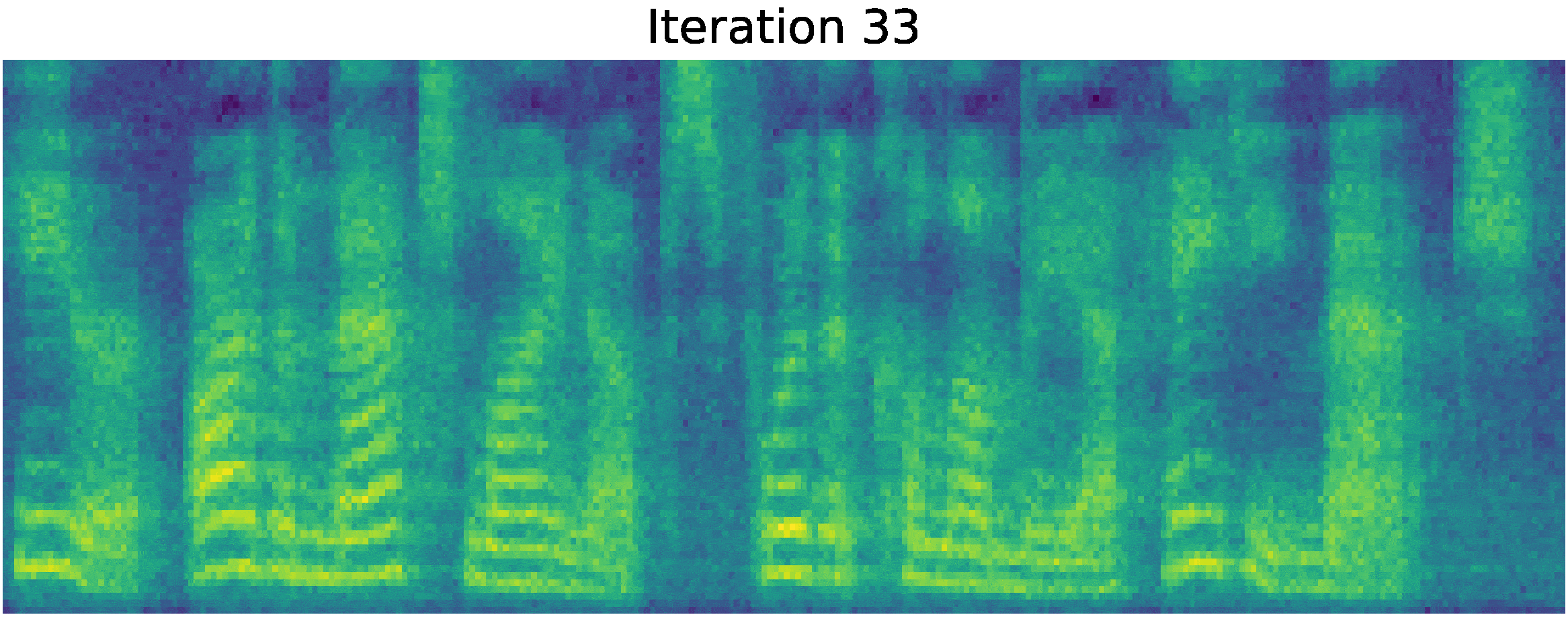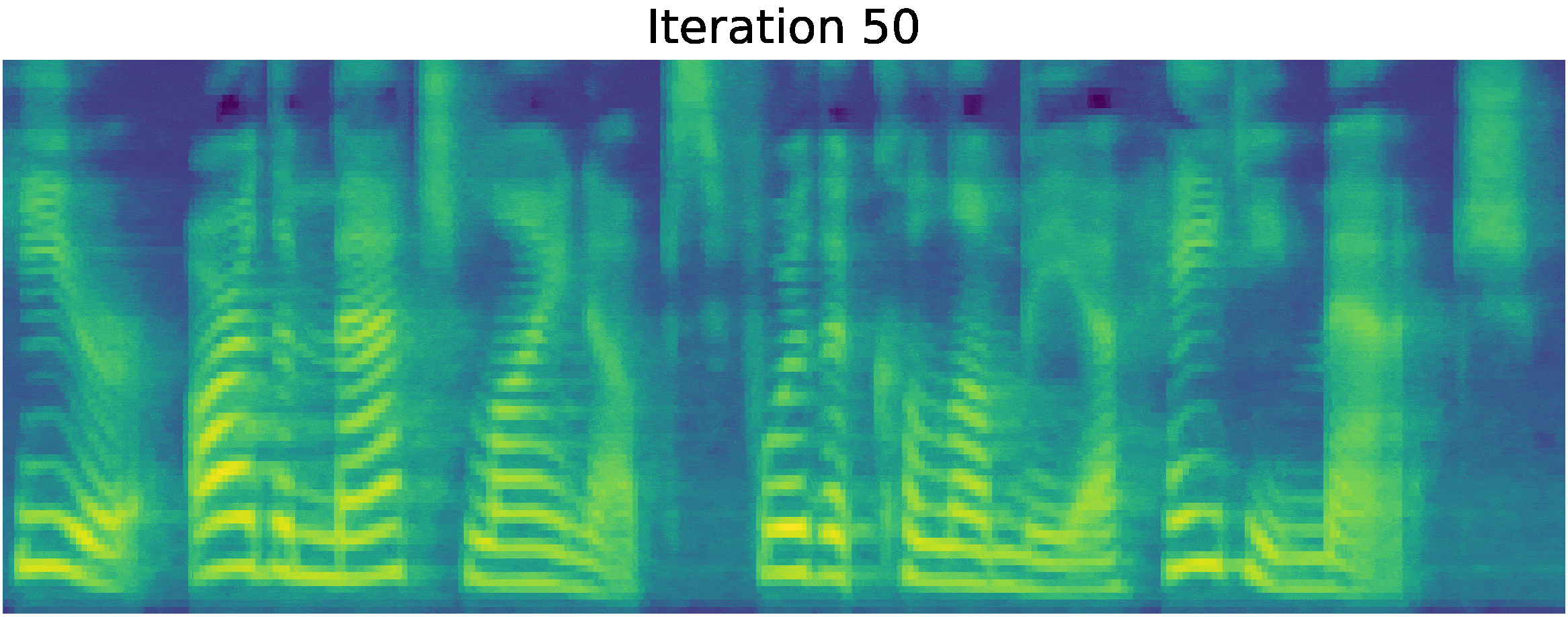
Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score. We will make the code publicly available shortly.
PDF AbstractCode



Datasets
 LJSpeech
LJSpeech
Results from the Paper
 Ranked #3 on
Text-To-Speech Synthesis
on LJSpeech
(using extra training data)
Ranked #3 on
Text-To-Speech Synthesis
on LJSpeech
(using extra training data)
