GraghVQA: Language-Guided Graph Neural Networks for Graph-based Visual Question Answering
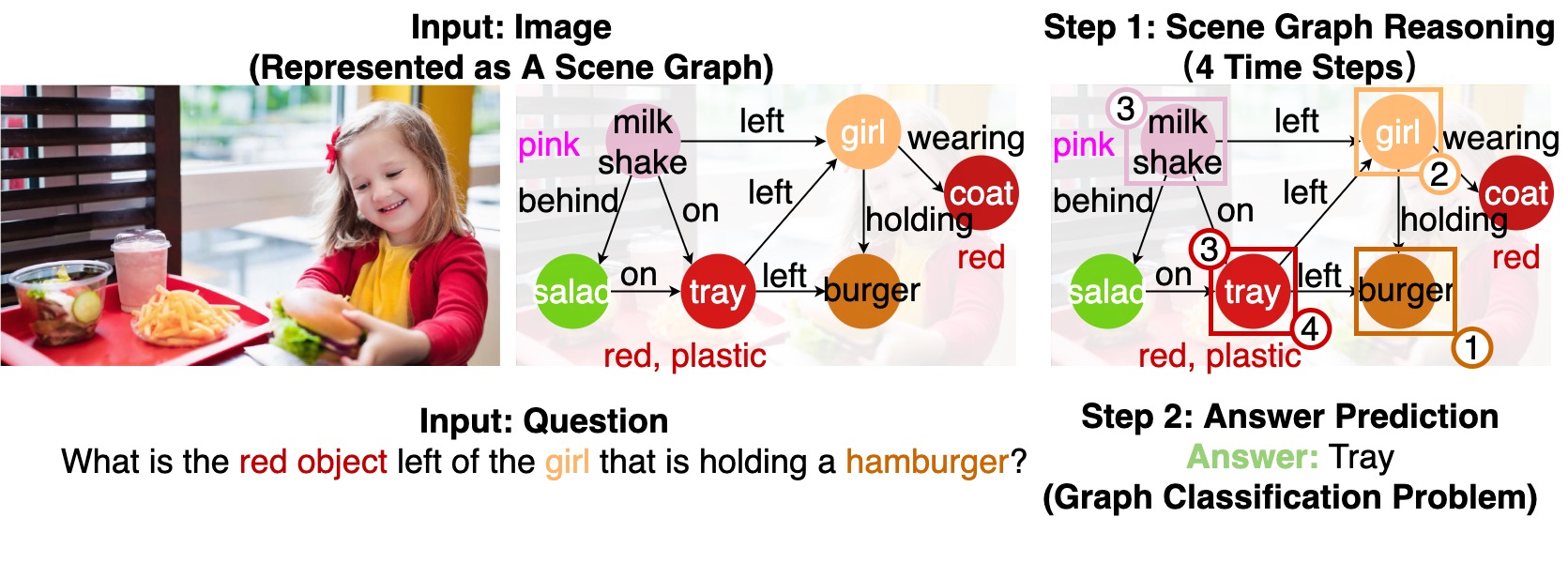
Images are more than a collection of objects or attributes -- they represent a web of relationships among interconnected objects. Scene Graph has emerged as a new modality for a structured graphical representation of images. Scene Graph encodes objects as nodes connected via pairwise relations as edges. To support question answering on scene graphs, we propose GraphVQA, a language-guided graph neural network framework that translates and executes a natural language question as multiple iterations of message passing among graph nodes. We explore the design space of GraphVQA framework, and discuss the trade-off of different design choices. Our experiments on GQA dataset show that GraphVQA outperforms the state-of-the-art model by a large margin (88.43% vs. 94.78%).
PDF Abstract NAACL (maiworkshop) 2021 PDF NAACL (maiworkshop) 2021 AbstractCode




Datasets
 GQA
GQA

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Graph Question Answering | GQA | GraphVQA | Accuracy | 96.30 | # 1 |
