GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
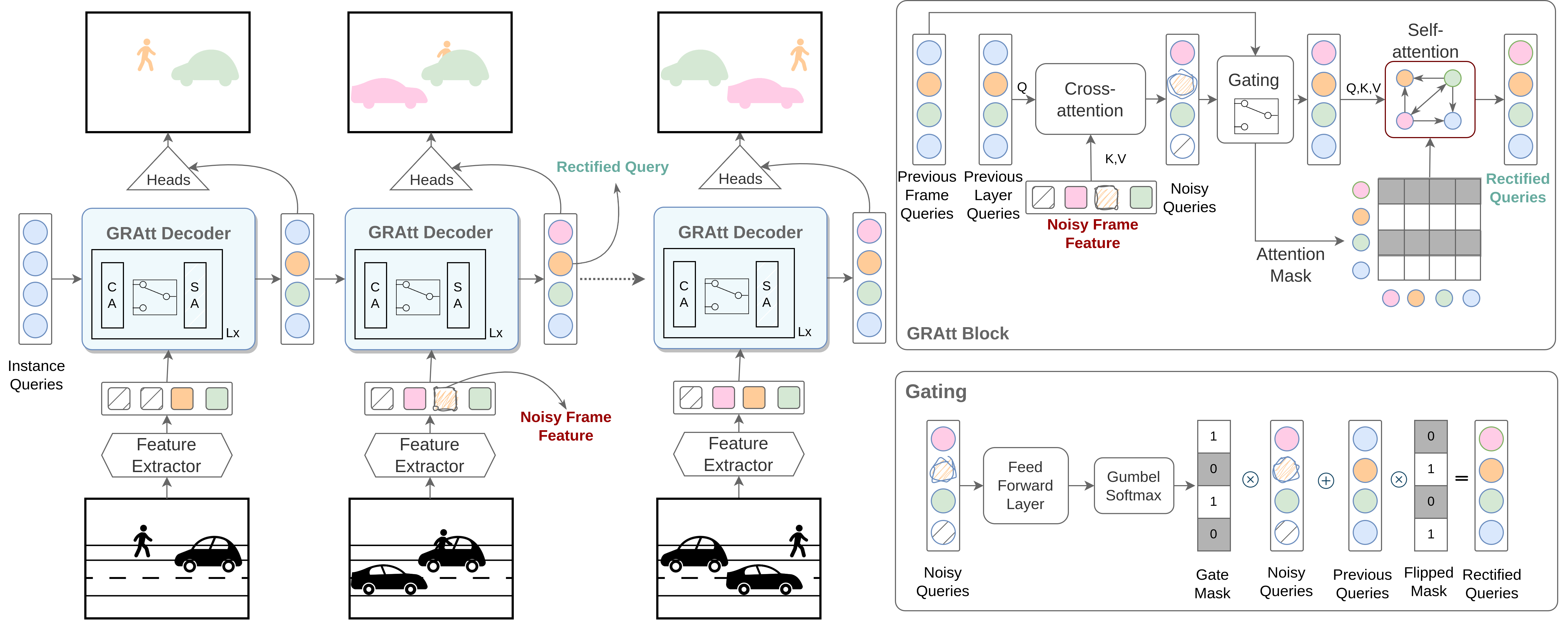
Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
PDF AbstractCode




Datasets
 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS
Results from the Paper
 Ranked #4 on
Video Instance Segmentation
on YouTube-VIS 2021
(using extra training data)
Ranked #4 on
Video Instance Segmentation
on YouTube-VIS 2021
(using extra training data)
