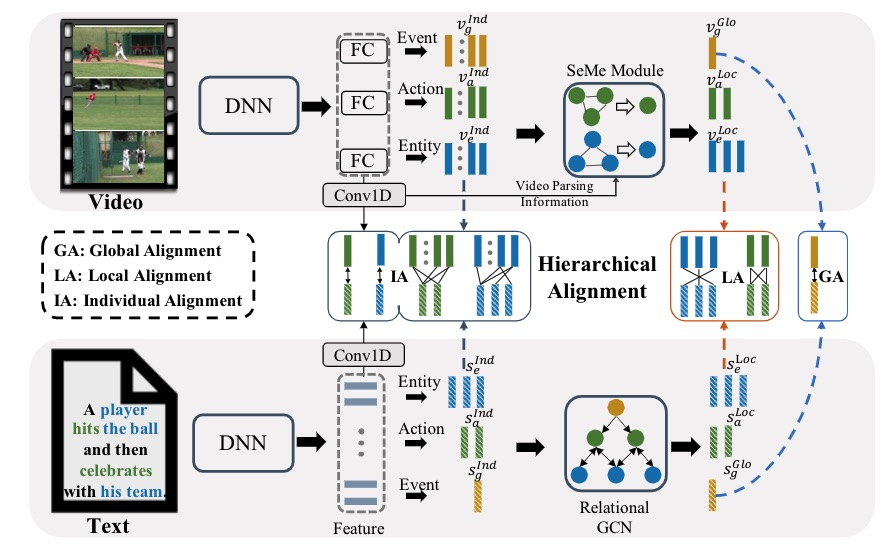
HANet: Hierarchical Alignment Networks for Video-Text Retrieval
Video-text retrieval is an important yet challenging task in vision-language understanding, which aims to learn a joint embedding space where related video and text instances are close to each other. Most current works simply measure the video-text similarity based on video-level and text-level embeddings. However, the neglect of more fine-grained or local information causes the problem of insufficient representation. Some works exploit the local details by disentangling sentences, but overlook the corresponding videos, causing the asymmetry of video-text representation. To address the above limitations, we propose a Hierarchical Alignment Network (HANet) to align different level representations for video-text matching. Specifically, we first decompose video and text into three semantic levels, namely event (video and text), action (motion and verb), and entity (appearance and noun). Based on these, we naturally construct hierarchical representations in the individual-local-global manner, where the individual level focuses on the alignment between frame and word, local level focuses on the alignment between video clip and textual context, and global level focuses on the alignment between the whole video and text. Different level alignments capture fine-to-coarse correlations between video and text, as well as take the advantage of the complementary information among three semantic levels. Besides, our HANet is also richly interpretable by explicitly learning key semantic concepts. Extensive experiments on two public datasets, namely MSR-VTT and VATEX, show the proposed HANet outperforms other state-of-the-art methods, which demonstrates the effectiveness of hierarchical representation and alignment. Our code is publicly available.
PDF Abstract

 MSR-VTT
MSR-VTT
