HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks
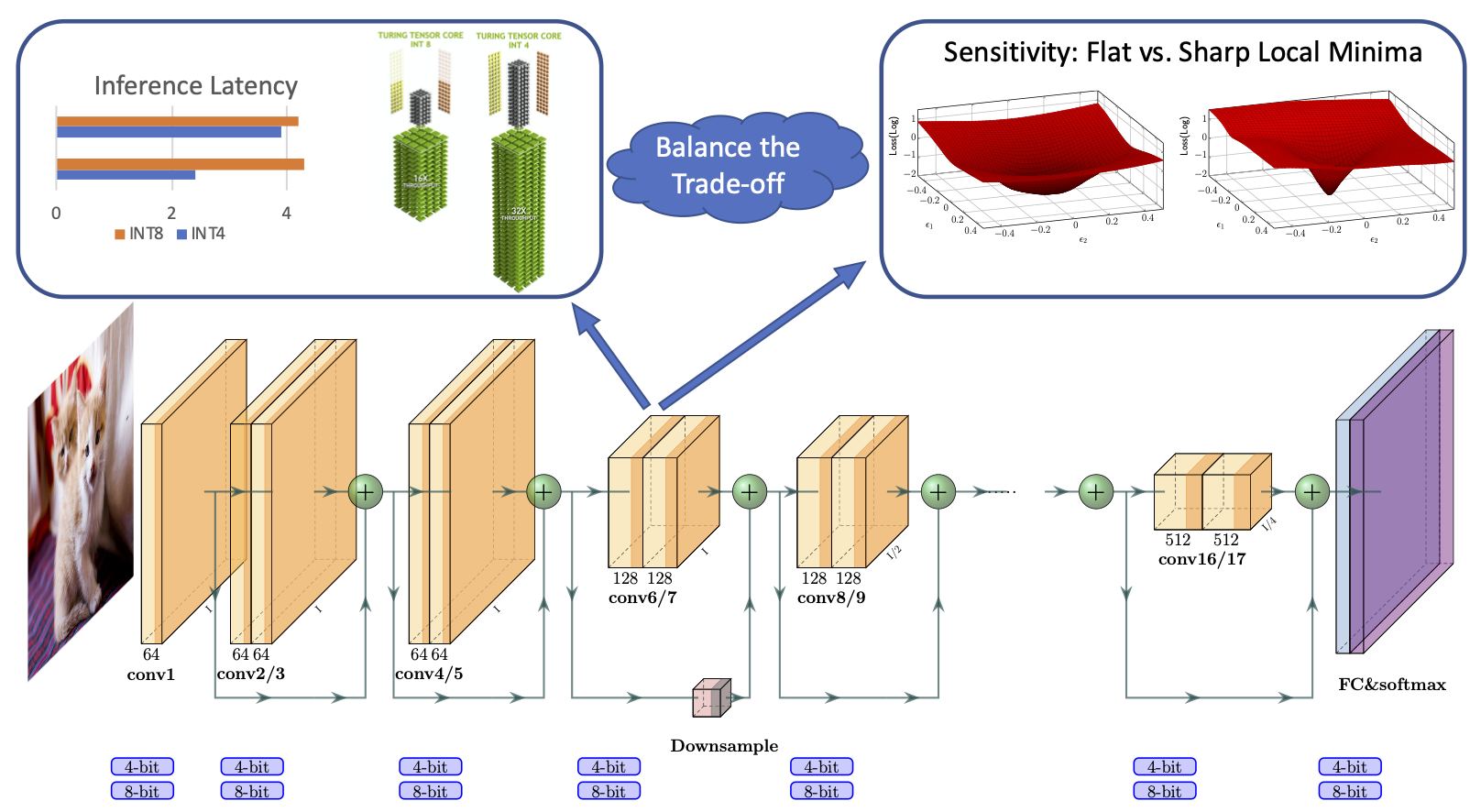
Quantization is an effective method for reducing memory footprint and inference time of Neural Networks, e.g., for efficient inference in the cloud, especially at the edge. However, ultra low precision quantization could lead to significant degradation in model generalization. A promising method to address this is to perform mixed-precision quantization, where more sensitive layers are kept at higher precision. However, the search space for a mixed-precision quantization is exponential in the number of layers. Recent work has proposed HAWQ, a novel Hessian based framework, with the aim of reducing this exponential search space by using second-order information. While promising, this prior work has three major limitations: (i) HAWQV1 only uses the top Hessian eigenvalue as a measure of sensitivity and do not consider the rest of the Hessian spectrum; (ii) HAWQV1 approach only provides relative sensitivity of different layers and therefore requires a manual selection of the mixed-precision setting; and (iii) HAWQV1 does not consider mixed-precision activation quantization. Here, we present HAWQV2 which addresses these shortcomings. For (i), we perform a theoretical analysis showing that a better sensitivity metric is to compute the average of all of the Hessian eigenvalues. For (ii), we develop a Pareto frontier based method for selecting the exact bit precision of different layers without any manual selection. For (iii), we extend the Hessian analysis to mixed-precision activation quantization. We have found this to be very beneficial for object detection. We show that HAWQV2 achieves new state-of-the-art results for a wide range of tasks.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 Abstract


 MS COCO
MS COCO
