HDI-Forest: Highest Density Interval Regression Forest
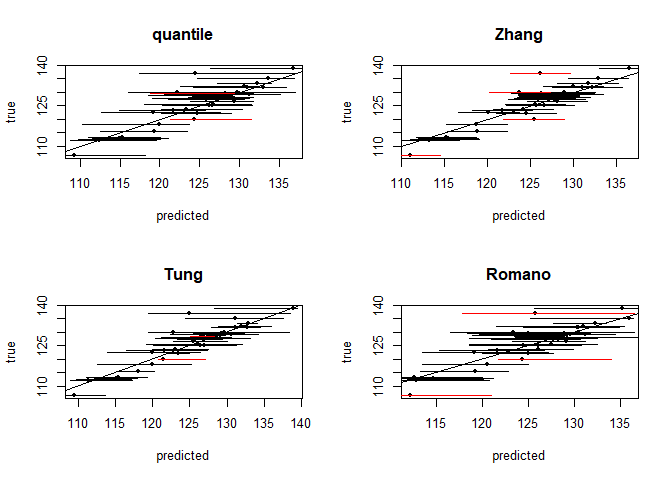
By seeking the narrowest prediction intervals (PIs) that satisfy the specified coverage probability requirements, the recently proposed quality-based PI learning principle can extract high-quality PIs that better summarize the predictive certainty in regression tasks, and has been widely applied to solve many practical problems. Currently, the state-of-the-art quality-based PI estimation methods are based on deep neural networks or linear models. In this paper, we propose Highest Density Interval Regression Forest (HDI-Forest), a novel quality-based PI estimation method that is instead based on Random Forest. HDI-Forest does not require additional model training, and directly reuses the trees learned in a standard Random Forest model. By utilizing the special properties of Random Forest, HDI-Forest could efficiently and more directly optimize the PI quality metrics. Extensive experiments on benchmark datasets show that HDI-Forest significantly outperforms previous approaches, reducing the average PI width by over 20% while achieving the same or better coverage probability
PDF Abstract
