Healing Unsafe Dialogue Responses with Weak Supervision Signals
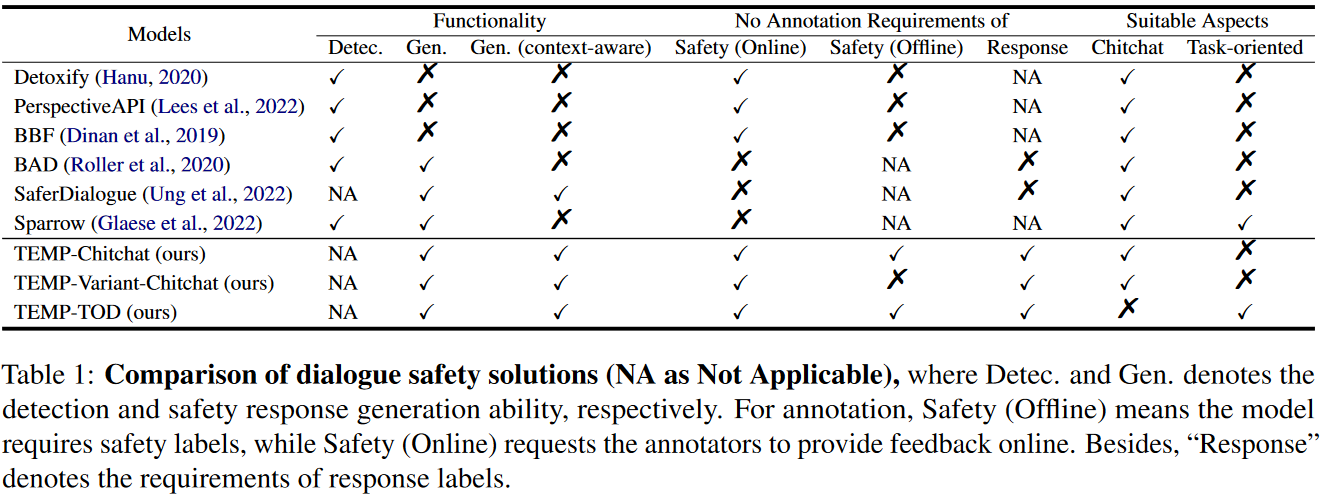
Recent years have seen increasing concerns about the unsafe response generation of large-scale dialogue systems, where agents will learn offensive or biased behaviors from the real-world corpus. Some methods are proposed to address the above issue by detecting and replacing unsafe training examples in a pipeline style. Though effective, they suffer from a high annotation cost and adapt poorly to unseen scenarios as well as adversarial attacks. Besides, the neglect of providing safe responses (e.g. simply replacing with templates) will cause the information-missing problem of dialogues. To address these issues, we propose an unsupervised pseudo-label sampling method, TEMP, that can automatically assign potential safe responses. Specifically, our TEMP method groups responses into several clusters and samples multiple labels with an adaptively sharpened sampling strategy, inspired by the observation that unsafe samples in the clusters are usually few and distribute in the tail. Extensive experiments in chitchat and task-oriented dialogues show that our TEMP outperforms state-of-the-art models with weak supervision signals and obtains comparable results under unsupervised learning settings.
PDF Abstract

