HERO: Hessian-Enhanced Robust Optimization for Unifying and Improving Generalization and Quantization Performance
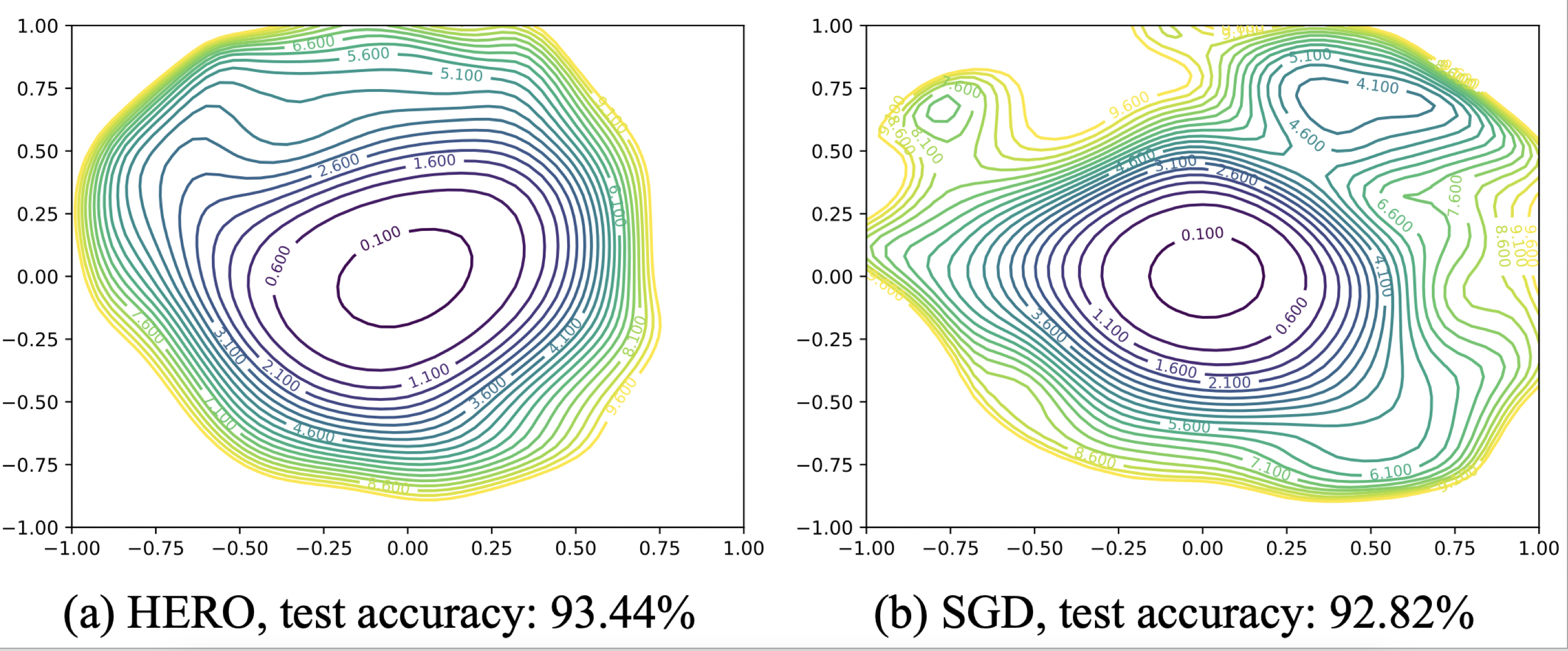
With the recent demand of deploying neural network models on mobile and edge devices, it is desired to improve the model's generalizability on unseen testing data, as well as enhance the model's robustness under fixed-point quantization for efficient deployment. Minimizing the training loss, however, provides few guarantees on the generalization and quantization performance. In this work, we fulfill the need of improving generalization and quantization performance simultaneously by theoretically unifying them under the framework of improving the model's robustness against bounded weight perturbation and minimizing the eigenvalues of the Hessian matrix with respect to model weights. We therefore propose HERO, a Hessian-enhanced robust optimization method, to minimize the Hessian eigenvalues through a gradient-based training process, simultaneously improving the generalization and quantization performance. HERO enables up to a 3.8% gain on test accuracy, up to 30% higher accuracy under 80% training label perturbation, and the best post-training quantization accuracy across a wide range of precision, including a >10% accuracy improvement over SGD-trained models for common model architectures on various datasets.
PDF Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
