Homogeneous Learning: Self-Attention Decentralized Deep Learning
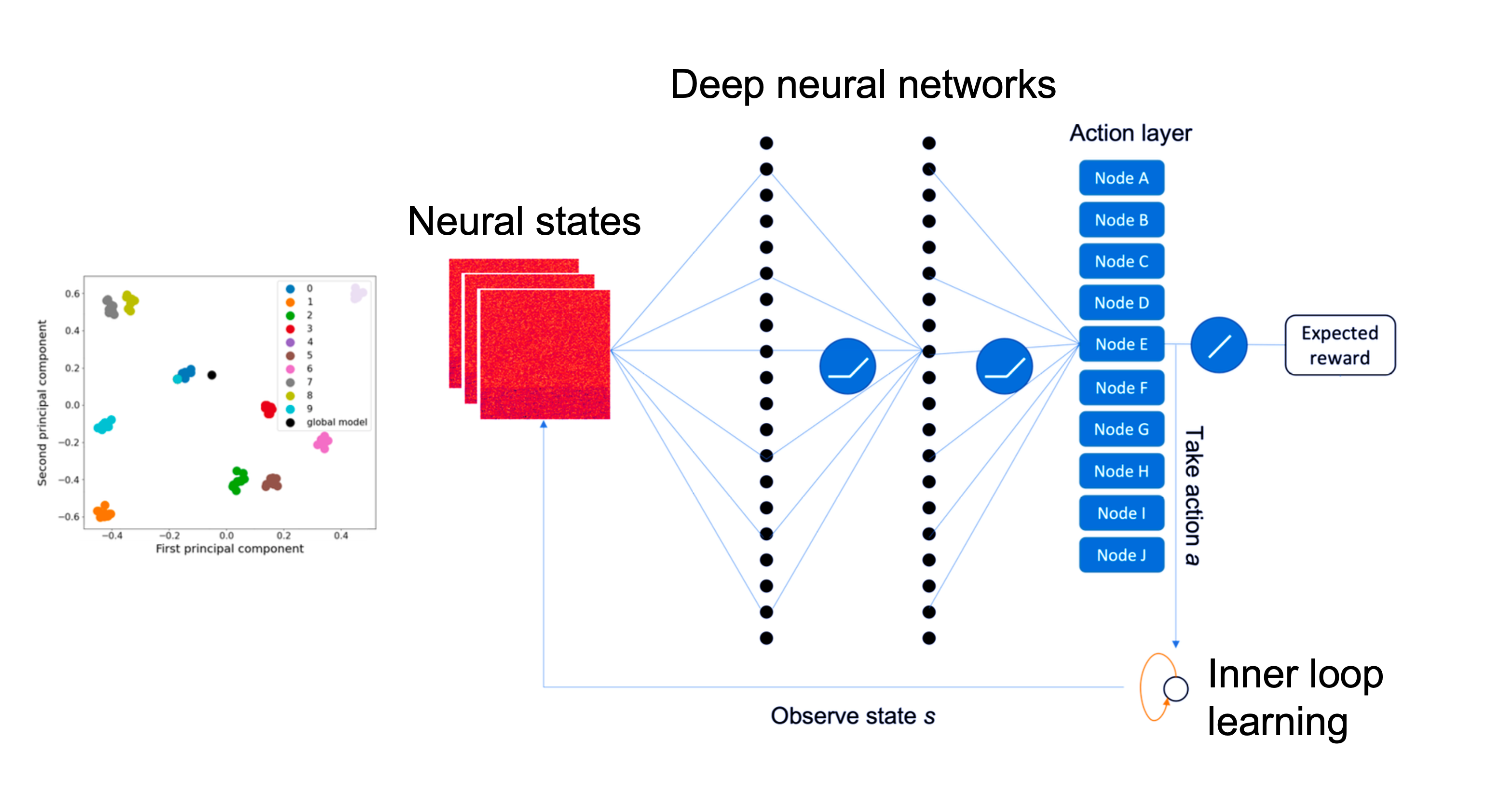
Federated learning (FL) has been facilitating privacy-preserving deep learning in many walks of life such as medical image classification, network intrusion detection, and so forth. Whereas it necessitates a central parameter server for model aggregation, which brings about delayed model communication and vulnerability to adversarial attacks. A fully decentralized architecture like Swarm Learning allows peer-to-peer communication among distributed nodes, without the central server. One of the most challenging issues in decentralized deep learning is that data owned by each node are usually non-independent and identically distributed (non-IID), causing time-consuming convergence of model training. To this end, we propose a decentralized learning model called Homogeneous Learning (HL) for tackling non-IID data with a self-attention mechanism. In HL, training performs on each round's selected node, and the trained model of a node is sent to the next selected node at the end of each round. Notably, for the selection, the self-attention mechanism leverages reinforcement learning to observe a node's inner state and its surrounding environment's state, and find out which node should be selected to optimize the training. We evaluate our method with various scenarios for an image classification task. The result suggests that HL can produce a better performance compared with standalone learning and greatly reduce both the total training rounds by 50.8% and the communication cost by 74.6% compared with random policy-based decentralized learning for training on non-IID data.
PDF Abstract




 MNIST
MNIST
 Fashion-MNIST
Fashion-MNIST
