How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
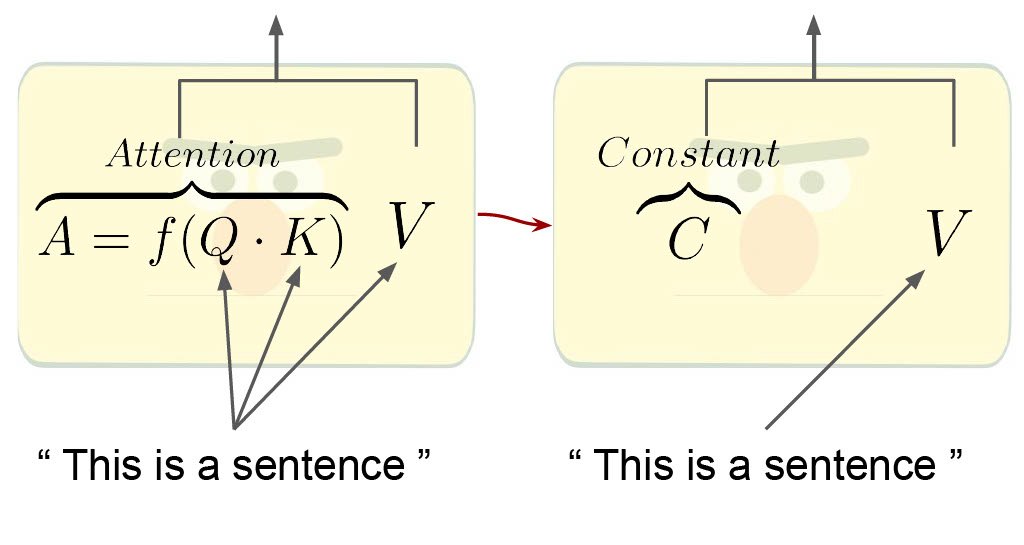
The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by computing input-specific attention matrices. We find that this mechanism, while powerful and elegant, is not as important as typically thought for pretrained language models. We introduce PAPA, a new probing method that replaces the input-dependent attention matrices with constant ones -- the average attention weights over multiple inputs. We use PAPA to analyze several established pretrained Transformers on six downstream tasks. We find that without any input-dependent attention, all models achieve competitive performance -- an average relative drop of only 8% from the probing baseline. Further, little or no performance drop is observed when replacing half of the input-dependent attention matrices with constant (input-independent) ones. Interestingly, we show that better-performing models lose more from applying our method than weaker models, suggesting that the utilization of the input-dependent attention mechanism might be a factor in their success. Our results motivate research on simpler alternatives to input-dependent attention, as well as on methods for better utilization of this mechanism in the Transformer architecture.
PDF Abstract
 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 MRPC
MRPC
 CoLA
CoLA
