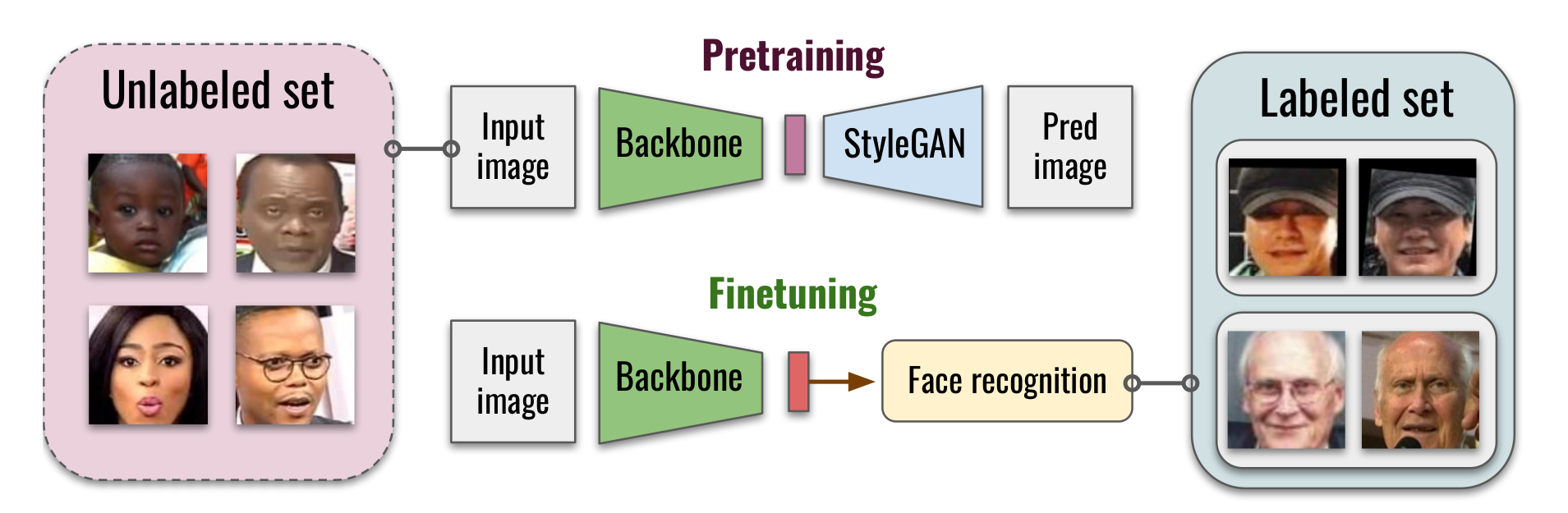
How to Boost Face Recognition with StyleGAN?
State-of-the-art face recognition systems require vast amounts of labeled training data. Given the priority of privacy in face recognition applications, the data is limited to celebrity web crawls, which have issues such as limited numbers of identities. On the other hand, self-supervised revolution in the industry motivates research on the adaptation of related techniques to facial recognition. One of the most popular practical tricks is to augment the dataset by the samples drawn from generative models while preserving the identity. We show that a simple approach based on fine-tuning pSp encoder for StyleGAN allows us to improve upon the state-of-the-art facial recognition and performs better compared to training on synthetic face identities. We also collect large-scale unlabeled datasets with controllable ethnic constitution -- AfricanFaceSet-5M (5 million images of different people) and AsianFaceSet-3M (3 million images of different people) -- and we show that pretraining on each of them improves recognition of the respective ethnicities (as well as others), while combining all unlabeled datasets results in the biggest performance increase. Our self-supervised strategy is the most useful with limited amounts of labeled training data, which can be beneficial for more tailored face recognition tasks and when facing privacy concerns. Evaluation is based on a standard RFW dataset and a new large-scale RB-WebFace benchmark. The code and data are made publicly available at https://github.com/seva100/stylegan-for-facerec.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

 MS-Celeb-1M
MS-Celeb-1M
