How to Design a Three-Stage Architecture for Audio-Visual Active Speaker Detection in the Wild
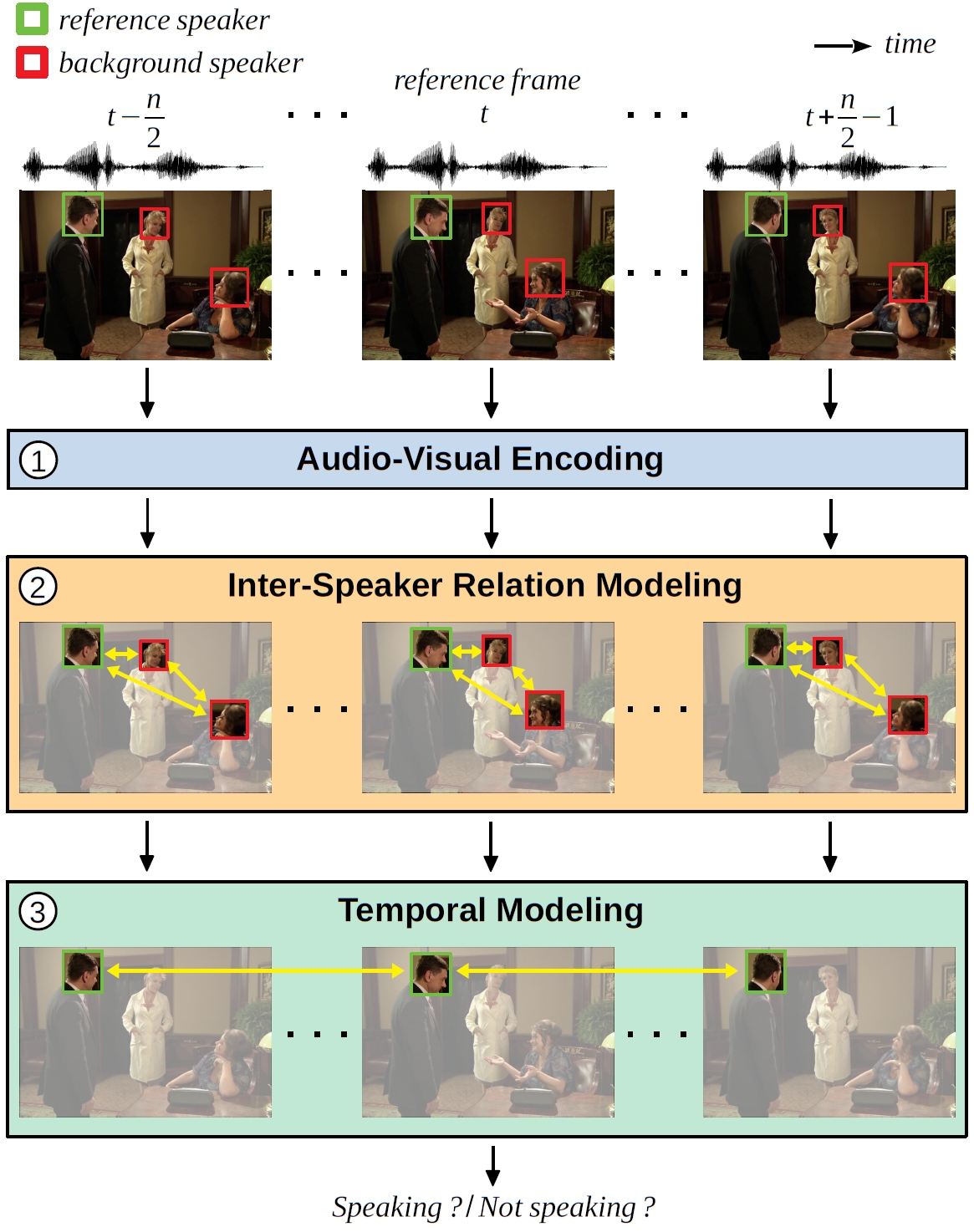
Successful active speaker detection requires a three-stage pipeline: (i) audio-visual encoding for all speakers in the clip, (ii) inter-speaker relation modeling between a reference speaker and the background speakers within each frame, and (iii) temporal modeling for the reference speaker. Each stage of this pipeline plays an important role for the final performance of the created architecture. Based on a series of controlled experiments, this work presents several practical guidelines for audio-visual active speaker detection. Correspondingly, we present a new architecture called ASDNet, which achieves a new state-of-the-art on the AVA-ActiveSpeaker dataset with a mAP of 93.5% outperforming the second best with a large margin of 4.7%. Our code and pretrained models are publicly available.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 Kinetics
Kinetics
 AVA
AVA
 AVA-ActiveSpeaker
AVA-ActiveSpeaker

