How to Train a CAT: Learning Canonical Appearance Transformations for Direct Visual Localization Under Illumination Change
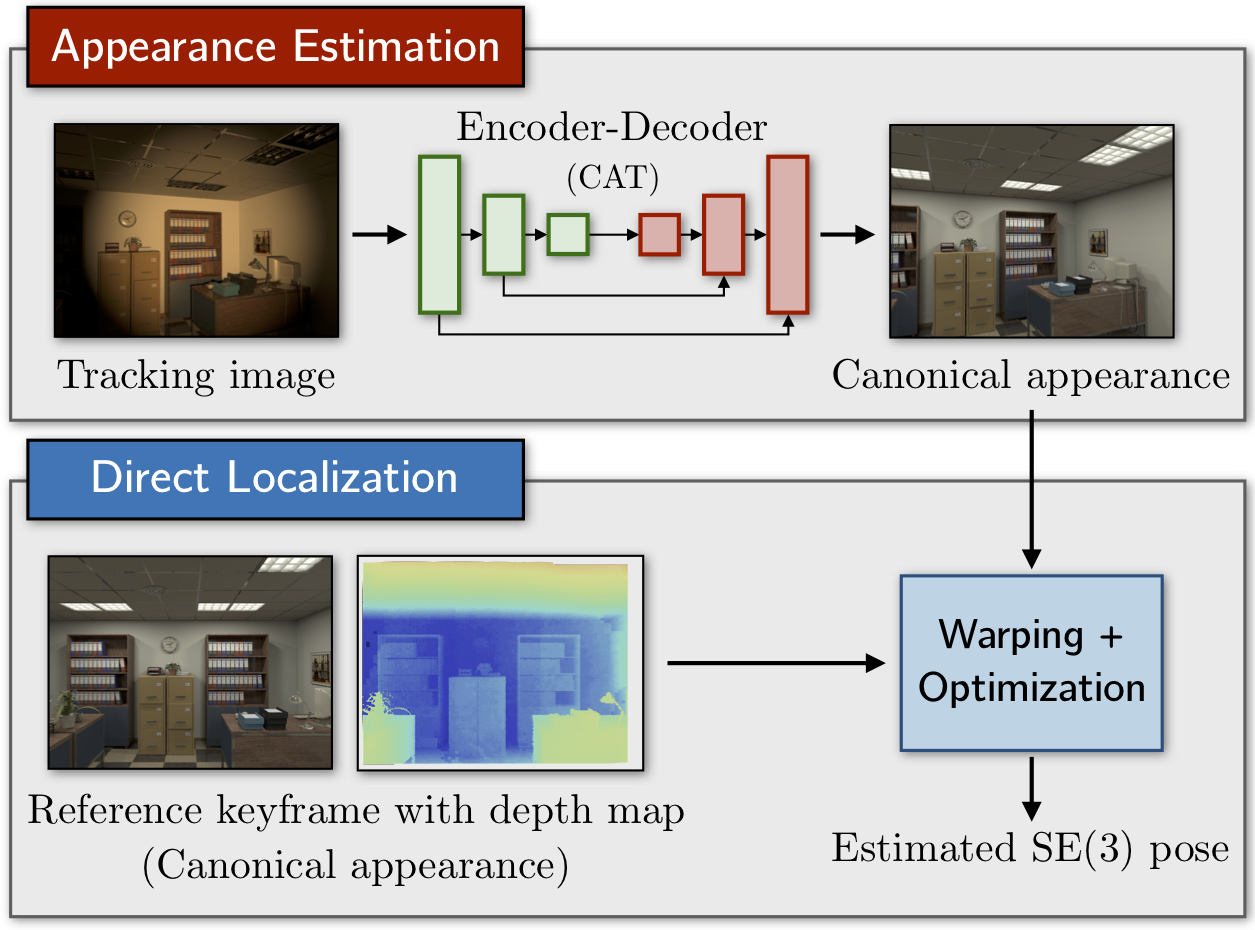
Direct visual localization has recently enjoyed a resurgence in popularity with the increasing availability of cheap mobile computing power. The competitive accuracy and robustness of these algorithms compared to state-of-the-art feature-based methods, as well as their natural ability to yield dense maps, makes them an appealing choice for a variety of mobile robotics applications. However, direct methods remain brittle in the face of appearance change due to their underlying assumption of photometric consistency, which is commonly violated in practice. In this paper, we propose to mitigate this problem by training deep convolutional encoder-decoder models to transform images of a scene such that they correspond to a previously-seen canonical appearance. We validate our method in multiple environments and illumination conditions using high-fidelity synthetic RGB-D datasets, and integrate the trained models into a direct visual localization pipeline, yielding improvements in visual odometry (VO) accuracy through time-varying illumination conditions, as well as improved metric relocalization performance under illumination change, where conventional methods normally fail. We further provide a preliminary investigation of transfer learning from synthetic to real environments in a localization context. An open-source implementation of our method using PyTorch is available at https://github.com/utiasSTARS/cat-net.
PDF Abstract


