Hybrid Transformers for Music Source Separation
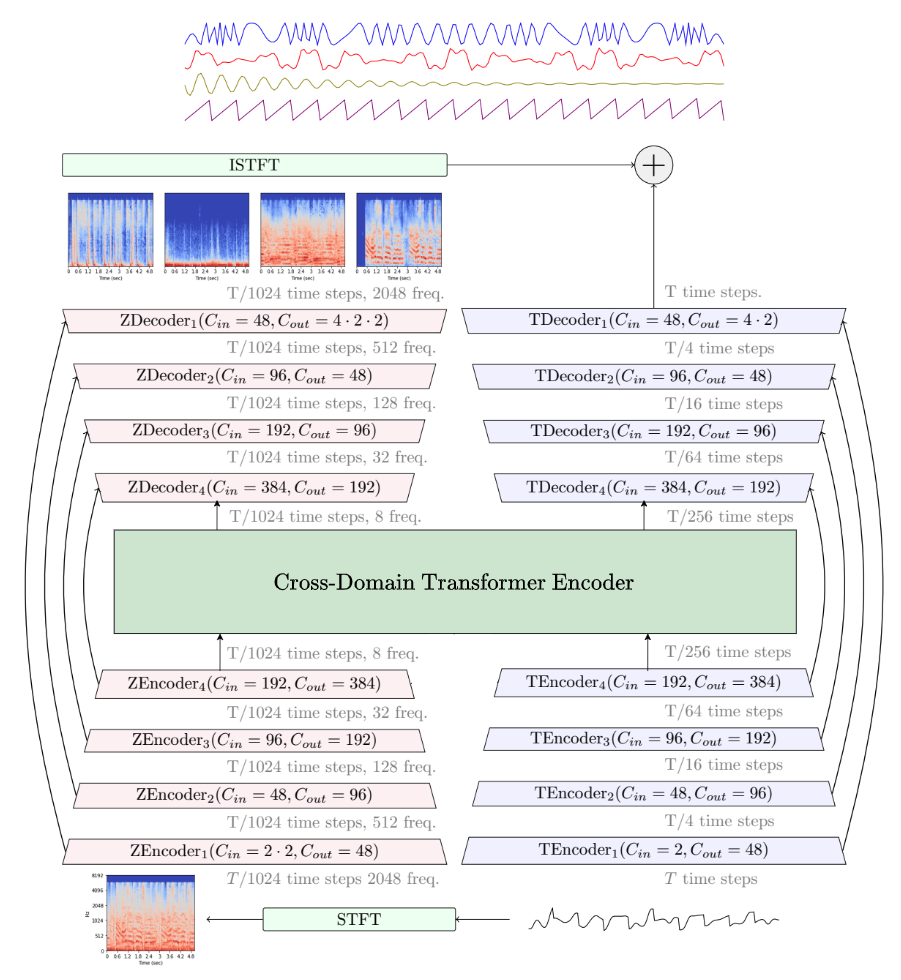
A natural question arising in Music Source Separation (MSS) is whether long range contextual information is useful, or whether local acoustic features are sufficient. In other fields, attention based Transformers have shown their ability to integrate information over long sequences. In this work, we introduce Hybrid Transformer Demucs (HT Demucs), an hybrid temporal/spectral bi-U-Net based on Hybrid Demucs, where the innermost layers are replaced by a cross-domain Transformer Encoder, using self-attention within one domain, and cross-attention across domains. While it performs poorly when trained only on MUSDB, we show that it outperforms Hybrid Demucs (trained on the same data) by 0.45 dB of SDR when using 800 extra training songs. Using sparse attention kernels to extend its receptive field, and per source fine-tuning, we achieve state-of-the-art results on MUSDB with extra training data, with 9.20 dB of SDR.
PDF AbstractCode
 Colab
Colab
 Spaces
Spaces

Tasks

Datasets
 MUSDB18
MUSDB18
 MUSDB18-HQ
MUSDB18-HQ
Results from the Paper
 Ranked #1 on
Music Source Separation
on MUSDB18
(using extra training data)
Ranked #1 on
Music Source Separation
on MUSDB18
(using extra training data)
