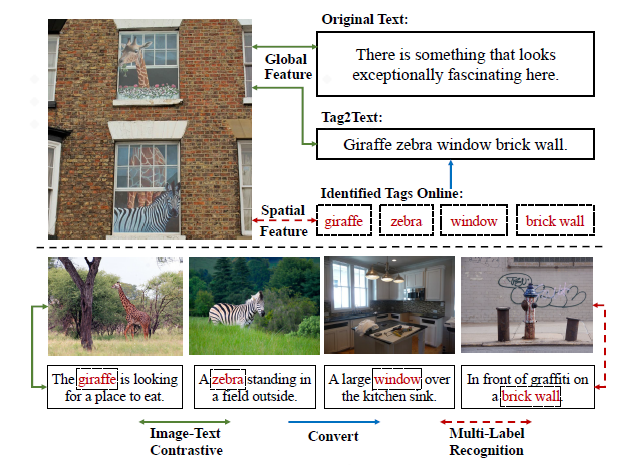
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
