Im2Avatar: Colorful 3D Reconstruction from a Single Image
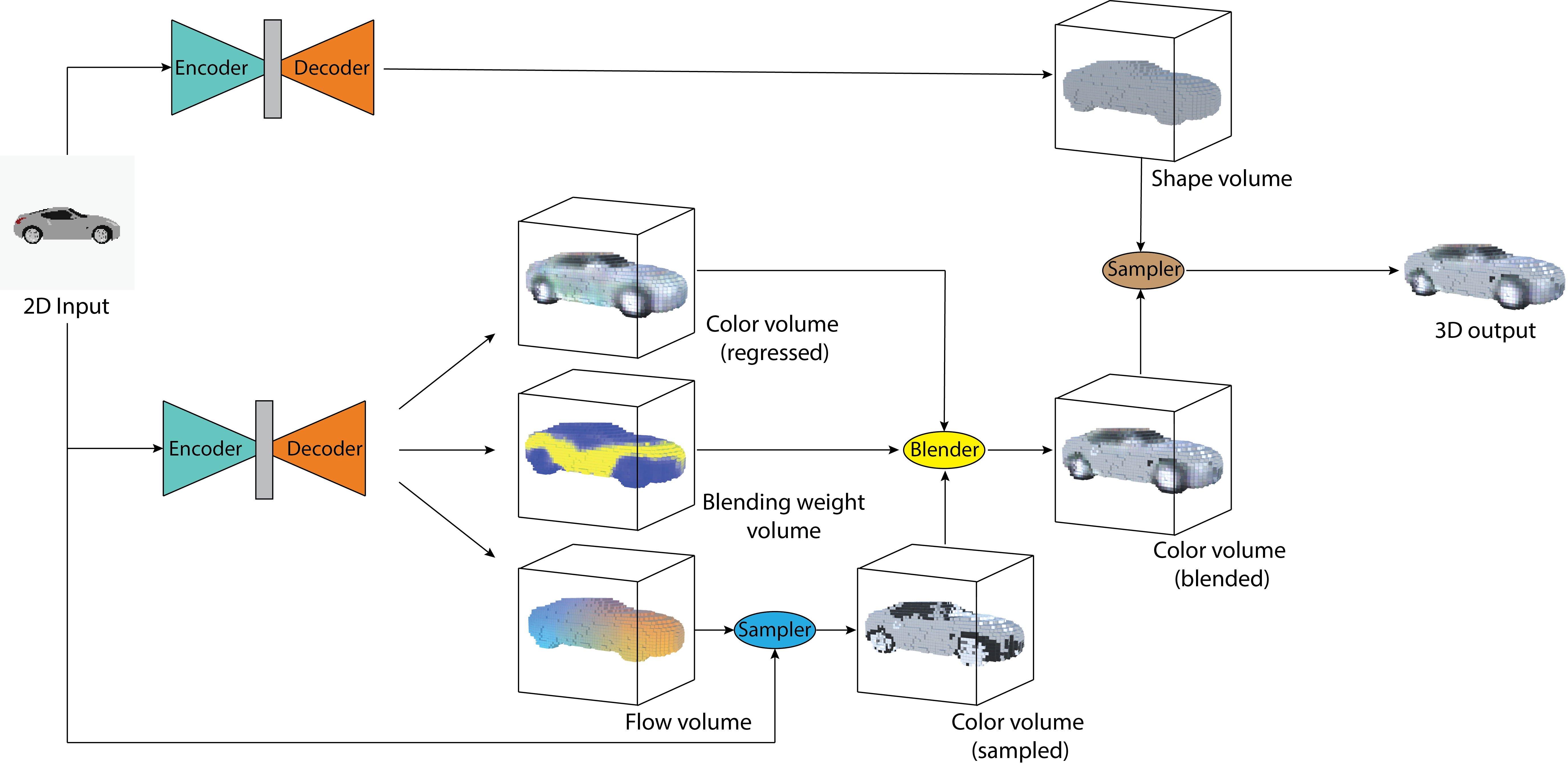
Existing works on single-image 3D reconstruction mainly focus on shape recovery. In this work, we study a new problem, that is, simultaneously recovering 3D shape and surface color from a single image, namely "colorful 3D reconstruction". This problem is both challenging and intriguing because the ability to infer textured 3D model from a single image is at the core of visual understanding. Here, we propose an end-to-end trainable framework, Colorful Voxel Network (CVN), to tackle this problem. Conditioned on a single 2D input, CVN learns to decompose shape and surface color information of a 3D object into a 3D shape branch and a surface color branch, respectively. Specifically, for the shape recovery, we generate a shape volume with the state of its voxels indicating occupancy. For the surface color recovery, we combine the strength of appearance hallucination and geometric projection by concurrently learning a regressed color volume and a 2D-to-3D flow volume, which are then fused into a blended color volume. The final textured 3D model is obtained by sampling color from the blended color volume at the positions of occupied voxels in the shape volume. To handle the severe sparse volume representations, a novel loss function, Mean Squared False Cross-Entropy Loss (MSFCEL), is designed. Extensive experiments demonstrate that our approach achieves significant improvement over baselines, and shows great generalization across diverse object categories and arbitrary viewpoints.
PDF Abstract


 ShapeNet
ShapeNet
