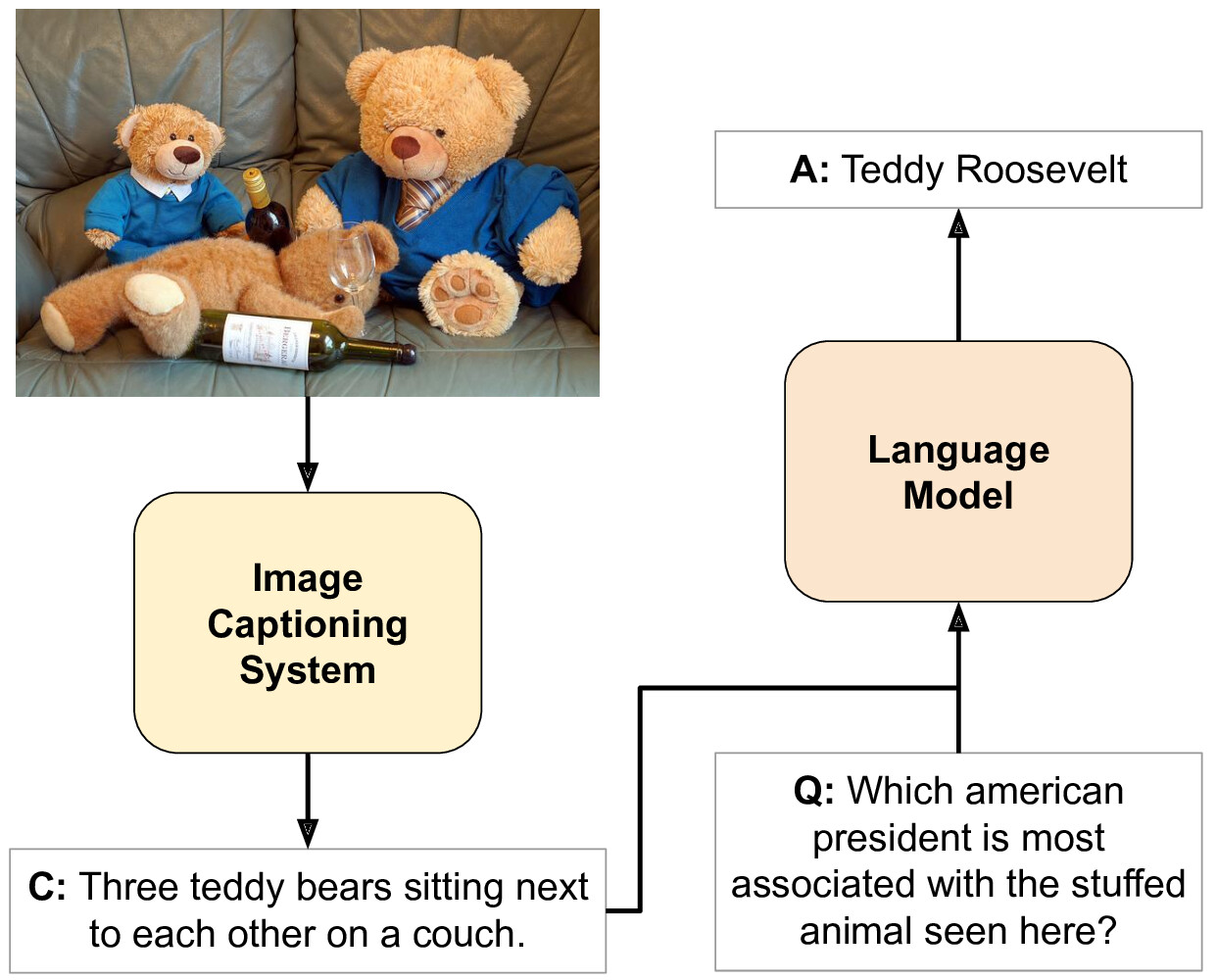
Image Captioning for Effective Use of Language Models in Knowledge-Based Visual Question Answering
Integrating outside knowledge for reasoning in visio-linguistic tasks such as visual question answering (VQA) is an open problem. Given that pretrained language models have been shown to include world knowledge, we propose to use a unimodal (text-only) train and inference procedure based on automatic off-the-shelf captioning of images and pretrained language models. Our results on a visual question answering task which requires external knowledge (OK-VQA) show that our text-only model outperforms pretrained multimodal (image-text) models of comparable number of parameters. In contrast, our model is less effective in a standard VQA task (VQA 2.0) confirming that our text-only method is specially effective for tasks requiring external knowledge. In addition, we show that increasing the language model's size improves notably its performance, yielding results comparable to the state-of-the-art with our largest model, significantly outperforming current multimodal systems, even though augmented with external knowledge. Our qualitative analysis on OK-VQA reveals that automatic captions often fail to capture relevant information in the images, which seems to be balanced by the better inference ability of the text-only language models. Our work opens up possibilities to further improve inference in visio-linguistic tasks
PDF Abstract




 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 ConceptNet
ConceptNet
 Visual Question Answering v2.0
Visual Question Answering v2.0
 OK-VQA
OK-VQA
